前戏
老花: 话接上回, 我们今天总结下MongoDB分片集群部署模式下, 需要注意一些地方。
分布式全量备份和恢复实践
首先, 明确一点, mongdump/mongorestore支持热备份和热恢复。
为了提升备份工作流的并发性能, 我们可以将命令改为多个shard同时后台下发, 那么如何确保这些备份任务及时下发和反馈进度呢?
我们可以引入一个管控面, 这可以是一个组件暴露成接口, 也可以是k8s上的一个job或者cronjob, 定时去执行。
不管怎么说, 它理论上应该有这些功能:
- 异步下发指令。
- 监控指令完成。
- 执行下一个指令。
- 最终返回备份成功或者失败的状态, 以及一些其他附加信息。
我们把这个流程画成时序图。
全备时序图
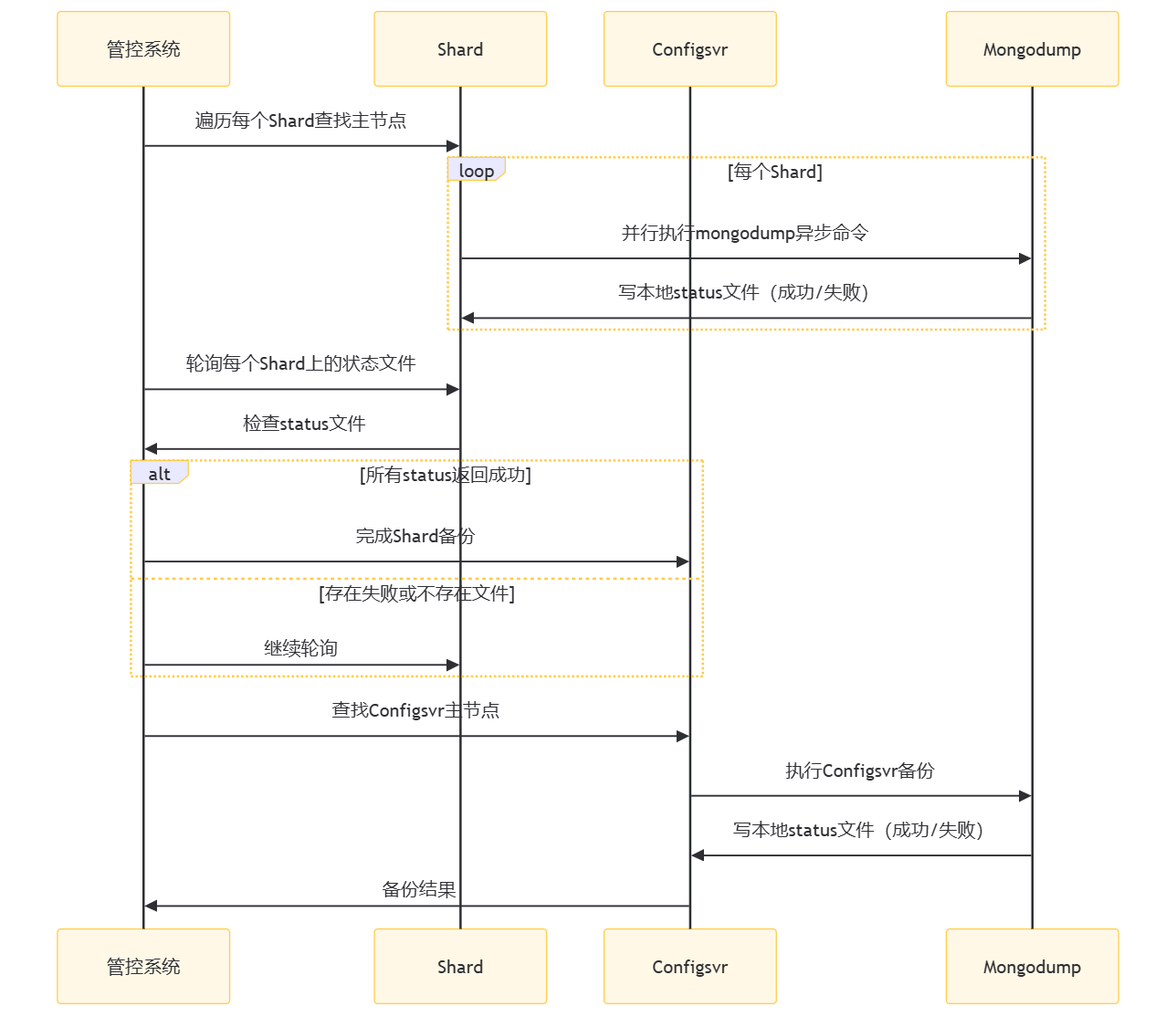
主要步骤:
- 管控系统遍历每个Shard查找主节点:管控系统首先需要确定每个分片(Shard)的主节点。
- 并行执行mongodump异步命令:对于每个Shard,管控系统并行执行mongodump命令来备份数据。这里需要进行二次封装,确保每次执行后都能写入一个本地的status文件,记录备份的成功或失败状态。
- 轮询每个Shard上的状态文件:管控系统需要轮询每个Shard上的状态文件,检查备份是否成功。如果所有Shard都返回成功,则备份成功;如果存在失败或文件不存在,则需要继续轮询。
- 完成Shard备份后执行Configsvr备份:一旦所有Shard的备份都成功完成,管控系统将开始备份Configsvr。这同样需要查找Configsvr的主节点,然后执行备份。
- Configsvr备份结果:Configsvr备份完成后,管控系统将收到备份结果,完成整个备份流程。
由此可见, 封装mongodump后的需要附加以下功能:
- 对接不同的灾备产品, 比如oss
- 对备份进行切分, 将备份上传到存储系统
- 上传备份数据到远程存储
全量恢复时序图
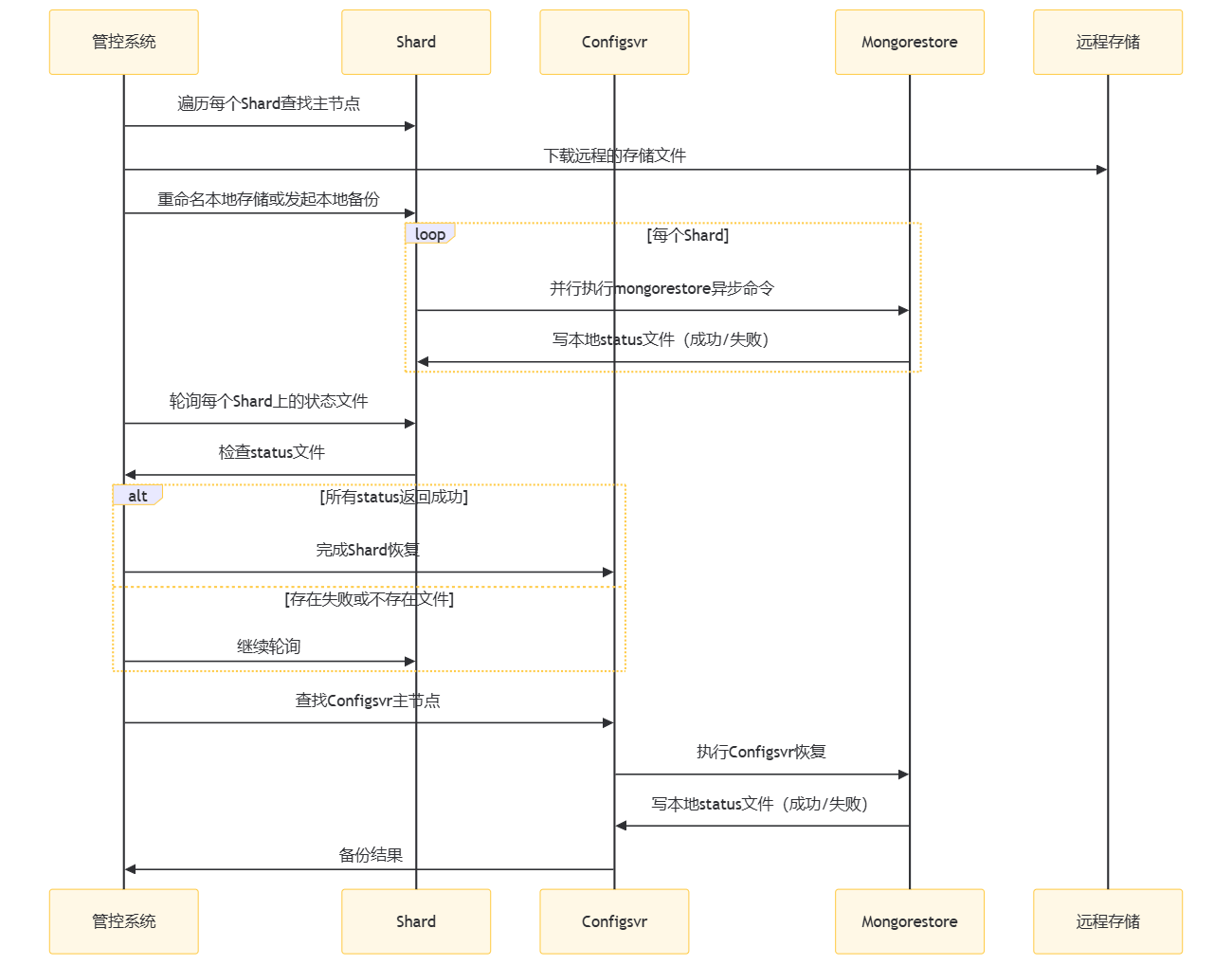
主要步骤:
- 管控系统遍历每个Shard查找主节点:管控系统首先需要确定每个分片(Shard)的主节点。
- 主节点上下载远程的存储文件:管控系统从远程存储下载备份文件。
- 重命名本地存储或发起本地备份:管控系统将下载的文件重命名或备份到本地存储,以便在恢复程序报错时支持数据回滚。
- 并行执行mongorestore异步命令:对于每个Shard,管控系统并行执行mongorestore命令来恢复数据。这里需要进行二次封装,确保每次执行后都能写入一个本地的status文件,记录恢复的成功或失败状态。
- 轮询每个Shard上的状态文件:管控系统需要轮询每个Shard上的状态文件,检查恢复是否成功。如果所有Shard都返回成功,则恢复成功;如果存在失败或文件不存在,则需要继续轮询。
- 完成Shard恢复后执行Configsvr恢复:一旦所有Shard的恢复都成功完成,管控系统将开始恢复Configsvr。这同样需要查找Configsvr的主节点,然后执行恢复。
- Configsvr恢复结果:Configsvr恢复完成后,管控系统将收到恢复结果,完成整个恢复流程。
上面的时序新增了远程存储, 但是恢复的时候需要先下载到容器中, 可能导致数据有可能的三份膨胀:
- 下载到本地的远程的备份
- 本节点的原有备份数据
- 恢复过程中的数据
除了数据膨胀, 如果原先孵化pod的pvc存储不够, 可能会直接导致失败。
可能有人会这样想:
- 直接把本地数据删除, 然后远程下载解压不香吗?
- 还有人这样想, 我直接搞个新集群, 恢复完了, 再重命名回来?
第一个问题, 可以是可以, 但是服务就相当于宕机了, 而且恢复失败, 回滚也是比较费事了。第二个问题呢, 云原生里面的设计, 多租户隔离比较常见的, 可能这么操作比较不优雅。
其实解决这个问题有很多思路:
- 先备份本地数据, 上传到oss后再删除, 就不占用空间了, 缺点是会对带宽有放大影响。
- 通过挂一个节点
hostpath, 先把数据放到这个挂了大存储的路径下, 恢复过程, 预留一倍的pv即可, 缺点是多个实例并发在某个节点上, 也有也能把把节点给打挂掉。当然啦, 我们可以通过任务注册, 监控或者告警来提前规避这个问题。 - ….
条条道路通长安, 条条道路是罗马。
由此可见, 封装mongorestore后的需要附加以下功能:
- 备份本地文件, 以免需要回归
- 下载远程备份数据到本地存储
- 解压
- 支持对切分后的备份进行恢复
- ….
增量备份与恢复时序图
了解完全量备份和恢复后, 增量备份就比较好实现了。
增量备份, 直接通过按照时间戳query和local.oplog.rs数据库中获取增量数据, 每次的增量备份, 需要记录这个备份的逻辑起止时间。必要的时候, 放在元数据中存储起来,似乎还可以存储一个md5以便文件校验需求。
但增量恢复则不同, 需要进行一次全量还原, 然后再执行增量还原。而且需要确保, 多个增量还原的数据的时间范围要是连续的。
为什么需要进行一次全量备份恢复?
- 假设, 你现在有个1点到2点的增量备份数据, 期望你的用户数据恢复到两点的数据。
- 如果你直接恢复, 进行操作日志回放的话, 可能之前操作的一些数据, 在2点之后发生了变化, 就会导致恢复数据不一致。比如, 新增了某个库表, 那么直接恢复并不会删除这些库表。
- 注意, 使用
mongorestore基于oplog进行数据恢复时,并不是进行反向操作,这与MySQL的undo log机制不同。这个过程并不是反向撤销操作,而是将原始的操作再次执行一遍。 - 但是, 你先进行一次全量备份, 数据一定会恢复的一点那个时间段, 这时候回放可能就不会有这个问题了。
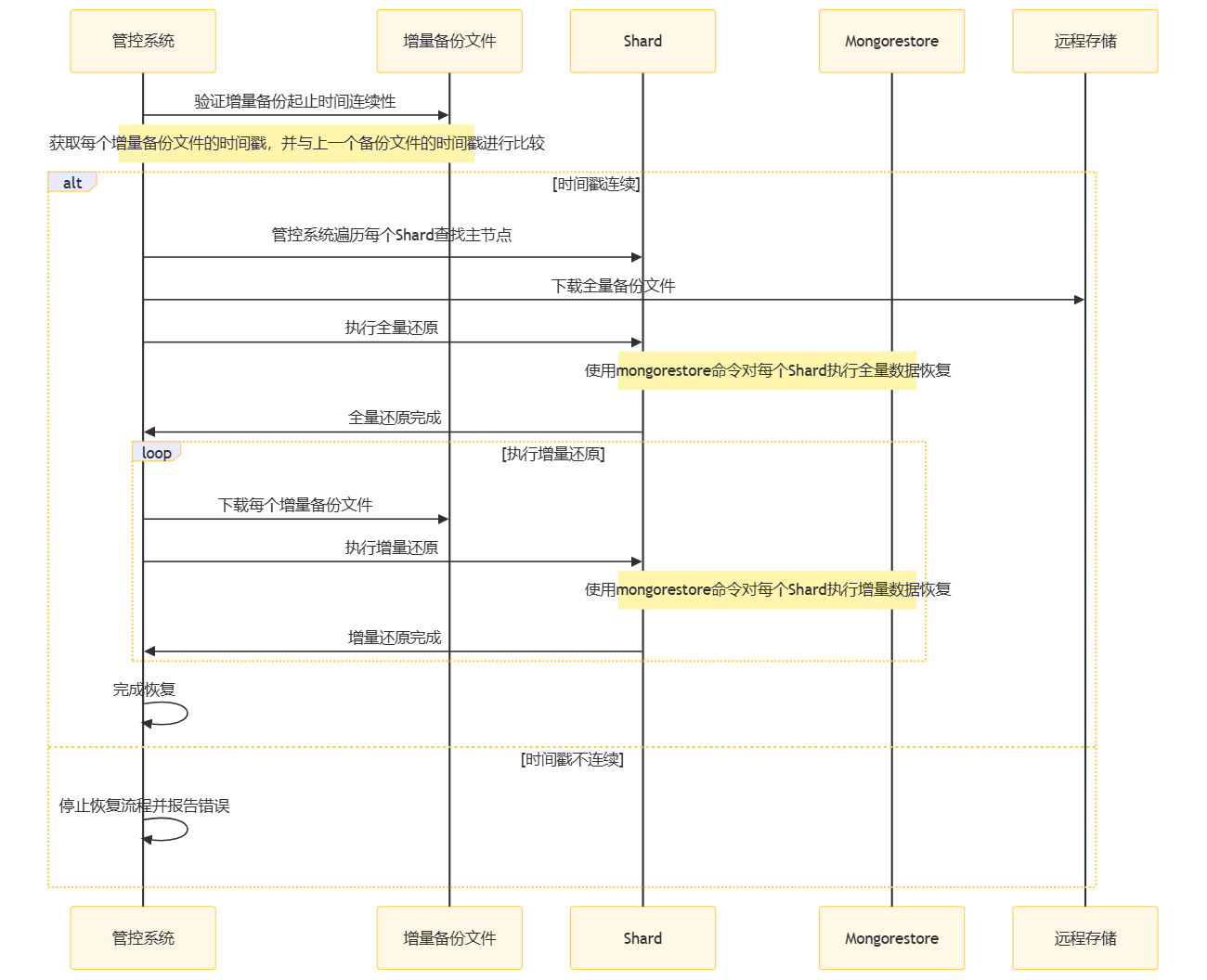
主要步骤:
- 备份完整性和增量备份连续性完整性验证。
- 管控系统遍历每个Shard查找主节点:管控系统确定每个分片(Shard)的主节点。
- 主节点上下载全量备份文件:管控系统从远程存储下载全量备份文件。
- 主节点上执行全量还原:管控系统使用mongorestore命令对每个Shard执行全量数据恢复。
- 全量还原完成:主节点上全量还原完成后,管控系统继续进行增量还原。
- 主节点上执行增量还原:管控系统下载每个增量备份文件,并使用mongorestore命令对每个Shard执行增量数据恢复。
- 完成恢复:所有增量还原完成后,管控系统完成整个恢复流程。
小尾巴
老花: 本期就讲这么多了, 下期再见~