前戏
今天我们聊聊使用 smolagents + ollama 打造本地私域可联网 agent
🌟 项目简介
smolagents 是一个轻量级库, 用于构建强大的代理(agents)。它允许用户通过几行代码运行功能强大的代理,支持多种语言模型(LLM)和工具。代理可以通过编写 Python 代码来调用工具并协调其他代理,非常适合快速开发和部署智能代理系统。
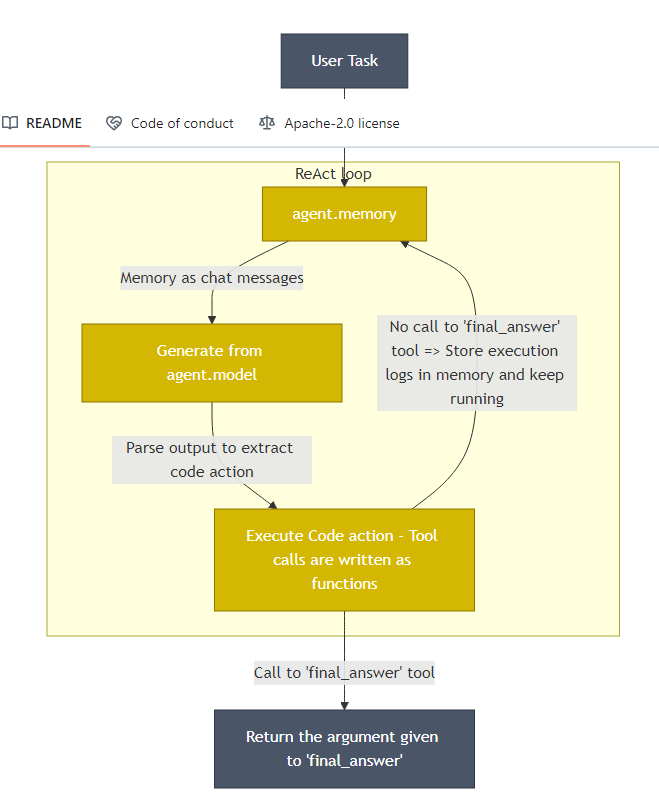
🚀 功能特点
极简设计:代理的核心逻辑仅约 1000 行代码,保持最小化的抽象层。
支持代码代理 CodeAgent :通过代码执行动作,支持在沙盒环境中运行以确保安全性
集成 Hugging Face Hub:支持从 Hub 共享和拉取工具。
模型无关性:支持任何 LLM。
多模态支持:支持文本、视觉、视频甚至音频输入。
工具无关性:支持 LangChain、Anthropic 的 MCP 等工具,甚至可以将 Hub Space 作为工具使用。
🛠️ 部署使用指南
📦 安装
通过 pip 安装 smolagents:
pip install smolagents
友情提示: 本地的 python 版本要求>=3.10
你可以参考这个方式进行升级:
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.10
python3.10 --version
# Python 3.10 默认可能不带 pip,需要手动安装:
sudo apt install python3.10-distutils
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3.10 get-pip.py
# 配置python3.10 为python3默认版本
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 1
sudo update-alternatives --config python3
🌐 支持的模型和工具
- HfApiModel:支持 Hugging Face Hub 上的模型。
- LiteLLMModel:通过 LiteLLM 集成访问 100+ LLM。
- OpenAIServerModel:支持 OpenAI 兼容的服务器。
- TransformersModel:支持本地 transformers 模型。
- AzureOpenAIServerModel:支持 Azure 上的 OpenAI 模型。
📟 CLI 工具
smolagents 提供了两个 CLI 命令:smolagent 和 webagent。
smolagents
smolagent:运行多步骤的 CodeAgent,支持多种工具。
smolagent "Plan a trip to Tokyo, Kyoto and Osaka between Mar 28 and Apr 7." --model-type "HfApiModel" --model-id "Qwen/Qwen2.5-Coder-32B-Instruct" --imports "pandas numpy" --tools "web_search translation"
webagent
webagent:专门用于网页浏览的代理。
webagent "go to xyz.com/men, get to sale section, click the first clothing item you see. Get the product details, and the price, return them. note that I'm shopping from France" --model-type "LiteLLMModel" --model-id "gpt-4o"
🚀 集成 ollama agent 示例
1. 创建一个 DuckDuckGo 搜索 agent
from smolagents import CodeAgent, LiteLLMModel, DuckDuckGoSearchTool
from litellm import LiteLLM
# 配置 Ollama 模型
model = LiteLLMModel(
model_id="ollama_chat/deepseek-r1:7b", # 格式是ollama_chat/xxx
base_url="http://192.168.137.112:11434",
api_key=None, # 默认为 None
num_ctx=8192
)
# 添加工具
tools = [DuckDuckGoSearchTool()] # 添加 DuckDuckGo 搜索工具
# 初始化 SmolAgents 的 CodeAgent
agent = CodeAgent(tools=tools, model=model, add_base_tools=True)
# 测试智能体
output = agent.run("What is the latest news about AI?")
print("Final output:")
print(output)
2. 创建一个多搜索 agent
from smolagents import (
CodeAgent,
LiteLLMModel,
DuckDuckGoSearchTool,
ToolCallingAgent,
VisitWebpageTool,
)
model = LiteLLMModel(
model_id="ollama_chat/deepseek-r1:7b", # 格式是ollama_chat/xxx
base_url="http://192.168.137.112:11434",
api_key=None, # 默认为 None
num_ctx=8192
)
search_agent = ToolCallingAgent(
tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
model=model,
name="search_agent",
description="This is an agent that can do web search.",
)
manager_agent = CodeAgent(
tools=[],
model=model,
managed_agents=[search_agent],
)
manager_agent.run("If the US keeps it 2024 growth rate, how many years would it take for the GDP to double?")
3. 创建一个 rag
https://github.com/huggingface/smolagents/blob/main/examples/rag_using_chromadb.py
import os
import datasets
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
# from langchain_community.document_loaders import PyPDFLoader
from langchain_huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
from transformers import AutoTokenizer
# from langchain_openai import OpenAIEmbeddings
from smolagents import LiteLLMModel, Tool
from smolagents.agents import CodeAgent
# from smolagents.agents import ToolCallingAgent
knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
source_docs = [
Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]}) for doc in knowledge_base
]
## For your own PDFs, you can use the following code to load them into source_docs
# pdf_directory = "pdfs"
# pdf_files = [
# os.path.join(pdf_directory, f)
# for f in os.listdir(pdf_directory)
# if f.endswith(".pdf")
# ]
# source_docs = []
# for file_path in pdf_files:
# loader = PyPDFLoader(file_path)
# docs.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
AutoTokenizer.from_pretrained("thenlper/gte-small"),
chunk_size=200,
chunk_overlap=20,
add_start_index=True,
strip_whitespace=True,
separators=["\n\n", "\n", ".", " ", ""],
)
# Split docs and keep only unique ones
print("Splitting documents...")
docs_processed = []
unique_texts = {}
for doc in tqdm(source_docs):
new_docs = text_splitter.split_documents([doc])
for new_doc in new_docs:
if new_doc.page_content not in unique_texts:
unique_texts[new_doc.page_content] = True
docs_processed.append(new_doc)
print("Embedding documents... This should take a few minutes (5 minutes on MacBook with M1 Pro)")
# Initialize embeddings and ChromaDB vector store
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma.from_documents(docs_processed, embeddings, persist_directory="./chroma_db")
class RetrieverTool(Tool):
name = "retriever"
description = (
"Uses semantic search to retrieve the parts of documentation that could be most relevant to answer your query."
)
inputs = {
"query": {
"type": "string",
"description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",
}
}
output_type = "string"
def __init__(self, vector_store, **kwargs):
super().__init__(**kwargs)
self.vector_store = vector_store
def forward(self, query: str) -> str:
assert isinstance(query, str), "Your search query must be a string"
docs = self.vector_store.similarity_search(query, k=3)
return "\nRetrieved documents:\n" + "".join(
[f"\n\n===== Document {str(i)} =====\n" + doc.page_content for i, doc in enumerate(docs)]
)
retriever_tool = RetrieverTool(vector_store)
# Choose which LLM engine to use!
# from smolagents import HfApiModel
# model = HfApiModel(model_id="meta-llama/Llama-3.3-70B-Instruct")
# from smolagents import TransformersModel
# model = TransformersModel(model_id="meta-llama/Llama-3.2-2B-Instruct")
# For anthropic: change model_id below to 'anthropic/claude-3-5-sonnet-20240620' and also change 'os.environ.get("ANTHROPIC_API_KEY")'
model = LiteLLMModel(
model_id="groq/llama-3.3-70b-versatile",
api_key=os.environ.get("GROQ_API_KEY"),
)
# # You can also use the ToolCallingAgent class
# agent = ToolCallingAgent(
# tools=[retriever_tool],
# model=model,
# verbose=True,
# )
agent = CodeAgent(
tools=[retriever_tool],
model=model,
max_steps=4,
verbosity_level=2,
)
agent_output = agent.run("How can I push a model to the Hub?")
print("Final output:")
print(agent_output)
4.自定义博客写作
https://github.com/zhu733756/cloud-database-tools/tree/master/llm/agents/smoleagents-examples
小尾巴
今天我们使用 ollama + deepseek + smolagents 给出了一系列离线 ai 代理的代码示例, 还是挺简单的!