前戏
今天我们聊聊大模型离线部署,用
Ollama怎么部署Qwen模型。
Ollama
Ollama是一个开源的 AI 模型服务, 旨在简化大型语言模型本地部署和运行过程的工具, 允许用户在无需 Internet 连接的情况下使用本地模型。
简化部署
一行命令跑起大模型:
ollama run llama3.2
当然, 运行前先保证ollama serve已经启动。环境变量配置 OLLAMA_HOST设置后端的地址。
简明的命令行风格
ollama --help
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
模型导入与定制
ModelFile
这是一个类似DockeFile的哲学设计,通过ModelFile可以快速构建一个模型镜像,然后通过ollama run 命令直接跑起一个模型:
$ cat Modelfile
FROM ./vicuna-33b.Q4_0.gguf
定制为本地模型:
$ ollama create vicuna:33b -f Modelfile
$ ollama run vicuna:33b
以下是 Modelfile 的一些关键点:
- 基础模型引用:Modelfile 中的 FROM 指令定义了创建模型时要使用的基础模型。这可以是现有的模型、Safetensors 模型,或者是 GGUF 文件中的模型。
- 参数设置:PARAMETER 指令用于设置 Ollama 运行模型时的参数,比如温度(temperature)、上下文窗口大小(num_ctx)等,这些参数影响模型的行为和输出。
- 提示模板:TEMPLATE 指令定义了发送给模型的完整提示模板,它包含了系统消息、用户输入和模型输出的结构。
- 系统消息:SYSTEM 指令指定了将在模板中设置的系统消息,这可以用于指定模型的行为,比如设定模型的角色或背景。
- 模型适配器:ADAPTER 指令定义了适用于模型的(Q)LoRA 适配器,这可能用于模型的特定优化或适配。
- 合法许可证:LICENSE 指令指定了模型的法律许可证,这对于模型的分发和使用非常重要。
- 消息历史:MESSAGE 指令用于指定消息历史记录,这有助于模型在对话中保持上下文的连贯性
指令包括 FROM(必需)、PARAMETER、TEMPLATE、SYSTEM、ADAPTER、LICENSE 和 MESSAGE 等。
支持多种模型格式
Safetensors
FROM <base model name>
ADAPTER /path/to/safetensors/adapter/directory # Safetensors adapter
FROM /path/to/safetensors/directory
GGUF
FROM <model name>
ADAPTER /path/to/file.gguf
FROM /path/to/file.gguf
REST API
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt":"Why is the sky blue?"
}'
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
详细 api 文档可以参考ollama api。
模型 ui 和集成
详见这里。
Open WebUI: 作为官方推荐的 UI,它很可能拥有较高的更新频率和活跃的社区支持。
这里推荐几个RAG(检索增强生成方法)相关的 UI 项目,包括简介和链接:
- Ollama RAG Chatbot: 使用 Ollama 和 RAG 进行本地聊天,支持多个 PDF 文件。
- CRAG Ollama Chat: 简单的 Web 搜索,结合了修正性 RAG。
- RAGFlow: 基于深度文档理解的开源检索增强生成引擎。
- ARGO: 在 Mac/Windows/Linux 上本地下载和运行 Ollama 和 Huggingface 模型,支持 RAG。
- Nosia: 基于 Ollama 的 RAG 平台,易于安装和使用。
- Minima: 支持本地或完全本地工作流程的 RAG。
- QA-Pilot: 交互式聊天工具,可以利用 Ollama 模型快速理解和导航 GitHub 代码库。
请注意,链接是指向 GitHub 上 Ollama 项目的相应部分,而不是直接的项目页面。您可能需要在 GitHub 页面上搜索这些项目名称以找到它们的具体页面。
离线部署
下载 ollama 和 Qwen 模型
ollama可以直接从官方的releases页面下载 ollama 的二进制文件,也可以从ollama的github仓库下载ollama的源码,编译后得到ollama的二进制文件, golang写的, 跨平台体验好。
Qwen模型可以到https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat-GGUF/tree/main或者执行ollama run qwen2:1.5b。
构建本地 qwen 模型
先准备ModleFile:
$ cat Modelfile
# Modelfile for Qwen 7B model
# 指定模型文件路径,这里假设模型文件已经下载并位于当前目录的models文件夹下
FROM ./models/qwen1_5-0_5b-chat-q8_0.gguf
# 设置模型参数
PARAMETER stop "<|im_start|>,<|im_end|>"
# 设置系统消息,这里可以根据需要自定义
SYSTEM """
You are an AI developed by Alibaba Cloud. Your purpose is to assist users in finding information and answering their questions.
"""
# 设置模板,用于定义模型的输入输出格式
TEMPLATE """
{{ if .System }}
<|im_start|>system
{{ .System }}
<|im_end|>
{{ end }}
{{ if .Prompt }}
<|im_start|>user
{{ .Prompt }}
<|im_end|>
{{ end }}
<|im_start|>assistant
{{ .Response }}
<|im_end|>
"""
# 设置许可证信息,这里只是一个示例,具体内容应根据实际许可证文件填写
LICENSE """
Tongyi Qianwen LICENSE AGREEMENT
Tongyi Qianwen Release Date: August 2023
This software is provided by Alibaba Cloud and is governed by the Tongyi Qianwen License Agreement.
"""
你如果要问这个ModelFile手写的, 那是万万不能的, 你可以从这个页面截图如下:
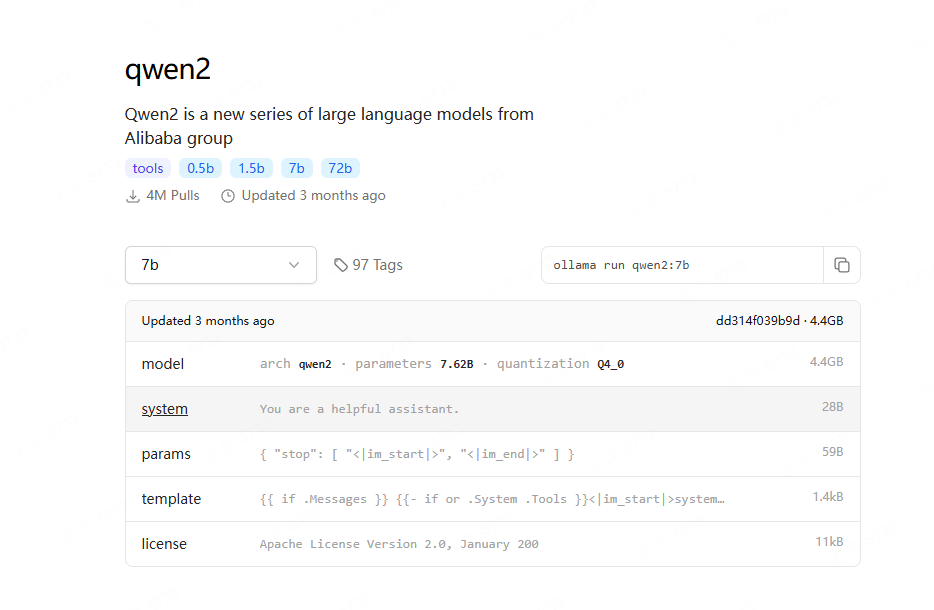
然后问Kimi: “把这个转成 ModelFile"即可。
完整流程如下, 一气呵成, 还是挺丝滑的:
$ mkdir models
$ mv qwen1_5-0_5b-chat-q8_0.gguf models/
$ ls
bin lib ModelFile models ollama-linux-amd64.tgz scripts
$ cat scripts/start.sh
#!/bin/bash
start_ollama() {
# 从不同路径查找ollama可执行文件
if [ -f "./bin/ollama" ]; then
OLLAMA_BIN="./bin/ollama"
elif [ -n "$OLLAMA_HOME" ] && [ -f "$OLLAMA_HOME/bin/ollama" ]; then
OLLAMA_BIN="$OLLAMA_HOME/bin/ollama"
else
OLLAMA_BIN="../bin/ollama"
fi
# 检查ollama是否已在运行
if [ -n "$(ps aux | grep 'ollama' | grep 'serve' | grep -v grep)" ]; then
echo "ollama-serve is already running. Stopping the process..."
kill $(ps aux | grep 'ollama' | grep 'serve' | grep -v grep | awk '{print $2}')
wait
fi
# 启动ollama serve
echo "Starting ollama-serve..."
nohup $OLLAMA_BIN serve > /dev/null 2>&1 &
echo "ollama-serve started."
}
# 检查是否需要重启
RESTART_FLAG=$1
if [ "$RESTART_FLAG" == "--restart" ]; then
start_ollama
elif [ -z "$(ps aux | grep 'ollama' | grep 'serve' | grep -v grep)" ]; then
start_ollama
else
echo "ollama-serve is running. Use --restart to restart the service."
fi
$ bash scripts/start.sh
$ cat scripts/source.sh
export OLLAMA_HOME=/root/llm/
alias ollama=$OLLAMA_HOME/bin/ollama
$ source scripts/source.sh
$ ollama list
NAME ID SIZE MODIFIED
$ ollama create qwen:5b -f ModelFile
transferring model data 100%
using existing layer sha256:af1878fcc3a949789b1ae6185852c242557b876a626f546e85c0bf719ff397d8
creating new layer sha256:ac1510262f71f3819b7ee1210ff525a2c85062d575752cbea4d867ff3e3acdf7
creating new layer sha256:4d76be5625f3798545b86a51ae588e092e4f63b7e4d02bd2e07c7f675f8c6728
creating new layer sha256:b5ef67d08c31f8fed9ce883c9d767733d9b517195c8745e97e74751b4f3741dd
creating new layer sha256:a269e0de2dfc0c0acd00a4bd26338faa46a63cf0953a4db05e037a842c843fbc
creating new layer sha256:9f7ae02b89a8964718e0df924a19aee23c333ac76490e58941d57da5df63dba4
writing manifest
success
$ ollama run qwen:5b
>>> 你是谁?
我是阿里云自主研发的超大规模语言模型“通义千问”,我叫阿里云自主研发的超大规模语言模型“通义千问”。
>>> 阿里云有mongodb产品吗?
是的,阿里云已经推出了名为“MongoDB”的产品。MongoDB是一款轻量级的NoSQL数据库,支持多种数据结构和操作模式,并且拥有分布式存储能力、高可用性和高性能等特性。
如果您有关于MongoDB的问题,欢迎随时提问。我会尽力回答您的问题。
>>> 1+1=?
2.
一些有用的命令汇总
- 创建模型:
ollama create <model_name> -f <path_to_Modelfile> - 拉取模型:
ollama pull <model_name> - 移除模型:
ollama remove <model_name> - 复制模型:
ollama cp <source_model> <destination_model> - 运行模型:
ollama run <model_name> - 多行输入:
ollama run <model_name> <<< """" ...你的多行文本... """ - 多模态模型:
ollama run <model_name> "<input_with_image_path>" - 传递提示作为参数:
ollama run <model_name> "<prompt>" - 显示模型信息:
ollama info <model_name> - 列出计算机上的模型:
ollama list - 列出模型的 modelfile 中的信息:
ollama show <model_name> --<flag> - 停止正在运行的模型:
ollama stop <model_name> - 启动 Ollama 服务:
ollama serve - 生成响应:
curl http://localhost:11434/api/generate -d '{ "model": "llama3.2", "prompt": "Why is the sky blue?" }' - 与模型聊天:
curl http://localhost:11434/api/chat -d '{ "model": "llama3.2", "messages": [{ "role": "user", "content": "why is the sky blue?" }] }'
小尾巴
- ollama是一个开源的
LLM服务器, 支持离线部署的体验真是丝滑如德芙。 - 下期我们搞个
webui体验下如何部署私有知识库, 顺便把我们之前的mongodb文档给喂进去看看。