前戏
前文, 我们使用
ollama离线部署了一个qwen-5b模型, 今天我们对RAG一些名词进行系统解释, 白话文解释, 再也不用懵逼了。
RAG是Retrieval-Augmented Generation的缩写, 中文意思是检索增强生成, 顾名思义, 没啥争议。
举个不恰当的例子, 想象你在写一篇关于小狗的文章, 但你对小狗的知识有限。RAG就像你使用搜索引擎查找关于小狗的信息, 然后将这些信息作为参考资料,来帮助你写出更全面的文章。至于增强的过程, 就是你通过整理这些参考资料, 去掉一些没用的, 甚至可能还会返回去图书馆找资料, 只为了给你的读者具象化地讲解, 最好是图文并茂。至于生成, 就是把检索增强后的文档丢给大模型, 然后由大模型回答问题。
除了这三个大概念外, 其实还有些预处理过程, 也是必不可少的优化手段。
我们按照顺序一一厘清, 尽可能覆盖所有的细节。
预处理
预处理是指用户输入和知识库构建的过程。可能涉及到的一些步骤如下。
数据清理
数据清理是RAG中一个重要的步骤, 它包括对原始数据进行预处理, 包括文本清理、实体识别、实体链接等。
分块
在 RAG 系统中, “分块”(Chunking)是指将长文本或文档分割成更小、更易于管理和处理的片段或块的过程。分块有利于提高检索效率, 改善上下文管理, 增强检索相关性。
以下是分块的一些优化手段:
- 固定大小分块(Fixed-size Chunking): 将文档分割成等长的块, 每个块包含固定数量的单词或字符。
- 结构化分块(Structured Chunking):根据文档的结构(如段落、标题、句子)来分割文档。
- 上下文丰富的分块(Context-rich Chunking):在分块时, 保留一些额外的上下文信息, 以便每个块都能提供足够的信息。确定合适的重叠量, 以便在块之间保持上下文的连贯性。
- 语义分块(Semantic Chunking): 基于文本的语义内容来分割文档, 确保每个块包含相关的概念或主题。使用 NLP 技术(如主题建模)来识别和分割语义上连贯的段落。
- 多模态分块(Multimodal Chunking)对于包含多种类型内容(文本、图像、视频)的文档, 采用适合不同模态的分块策略。为每种内容类型定制分块方法, 以保留各自的语义信息。
- …
知识库构建
知识库是RAG的核心, 它包含所有与用户需求相关的信息, 如文档、问题、实体等。
- 实体识别和链接: 在文本中识别出实体(如人名、地点、组织等), 并将它们与知识库中的相应条目链接起来。
- 知识提取: 从文本中提取结构化信息, 如事实、关系和概念, 并将它们存储在知识库中。
- 知识表示和存储: 选择合适的数据模型来表示知识, 如语义网络、图数据库、向量数据库等。
- 索引构建: 为知识库中的数据构建索引, 以加快检索速度。
检索分类器
确定哪些请求是否要走检索, 大模型的知识储备是否已经足够。如果已经足够, 直接跳过检索, 避免频繁的检索导致性能下降。
查询改写
查询改写是为了更好的增强检索过程。
- 同义词扩展: 将查询中的关键词替换或扩展为其同义词, 以增加检索的覆盖面。
- 上下位词扩展: 添加查询词的上下位词, 以扩展查询的语义范围。
- 拼写纠错: 自动识别并纠正查询中的拼写错误。
- 查询意图识别: 识别用户的查询意图, 并据此改写查询以更好地匹配知识库中的内容。
- 关键词提取: 从用户查询中提取关键词, 并基于这些关键词构建或优化查询。
- 短语重构: 将查询中的短语改写为更常见或更精确的表达方式。
- 布尔运算符应用: 在查询中添加或修改布尔运算符(AND, OR, NOT)以细化搜索条件。
- 语言模型应用:利用预训练的语言模型来生成查询的变体或改进查询。
- …
检索
RAG的检索, 是指从知识库中, 检索出与用户输入最匹配的知识, 然后将知识与用户输入进行结合, 生成答案。这就像你去图书馆找书, 你根据你的需求(比如"小狗的习性")来搜索相关的资料。
用什么检索? 指标是什么?
关键词检索(Keyword Search)
关键词检索是最传统和直观的检索方法, 它依赖于文档中特定关键词的出现。这种方法在实现简单、响应快速和对用户友好方面有优势, 尤其是在用户有明确关键词需求时。它也是许多搜索引擎的基础, 比如ES。
TF-IDF是一种基于关键词重要性的统计方法, 用于评估一个词在文档集合中的重要性。它通过词频(TF)和逆文档频率(IDF)的乘积来量化。TF-IDF 高的词被认为对文档具有较好的区分度。BM25是一种基于概率排名函数的算法, 用于估计查询词与文档的相关性。它是 TF-IDF 的改进版本, 考虑了文档长度对词频的影响, 以避免长文档因包含更多词而自动获得更高的相关性评分。
相似度检索(Similarity Search)
向量数据库检索
向量数据库检索的一般流程如下:
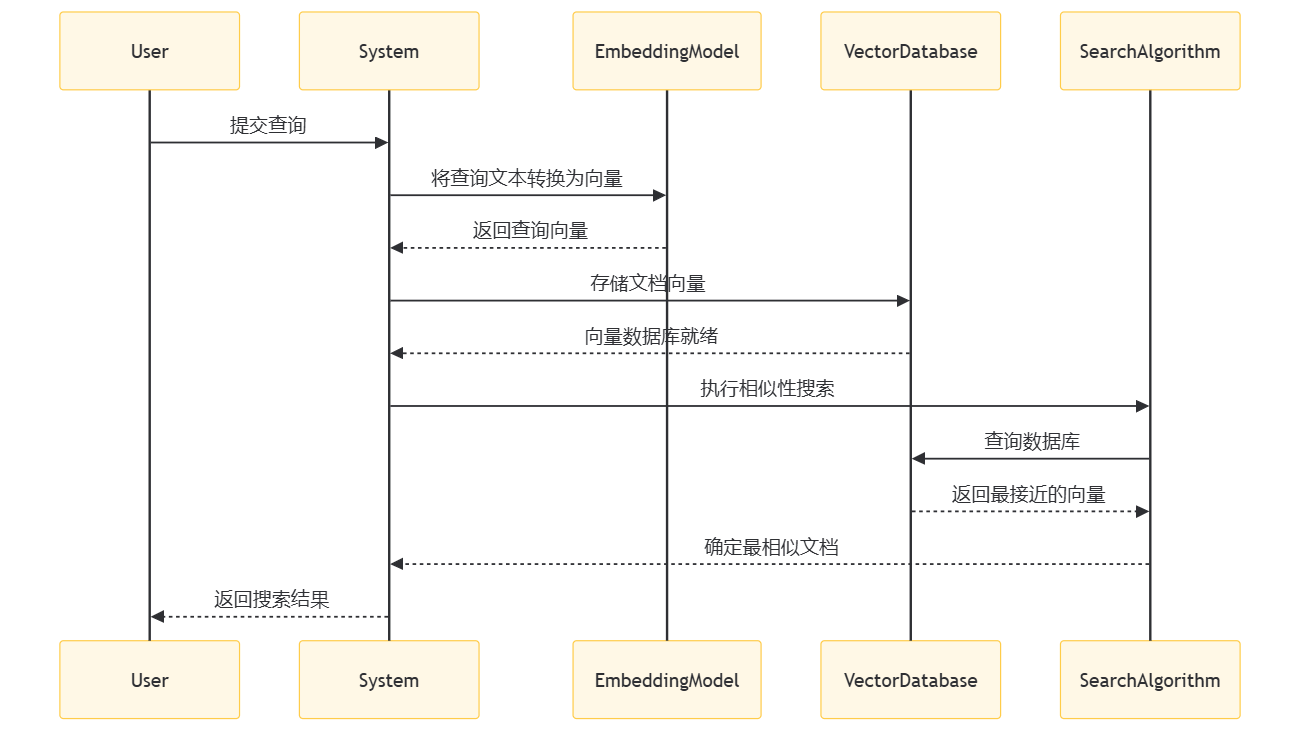
- User:用户向系统提交查询。
- System:系统接收用户查询, 并开始处理流程。
- EmbeddingModel:系统使用嵌入模型(如 BERT 或 Word2Vec)将用户的查询文本转换为向量形式。
- VectorDatabase:系统将文档向量存储在向量数据库中, 以便进行高效的相似性搜索。
- SearchAlgorithm:当用户查询被转换为向量后, 系统执行相似性搜索算法。
- VectorDatabase:搜索算法向向量数据库发出查询, 请求最接近的向量。
- SearchAlgorithm:向量数据库返回与查询向量最接近的文档向量。
- System:系统确定最相似的文档, 并将其作为搜索结果返回给用户。
图数据库检索
图数据库检索的一般流程如下:
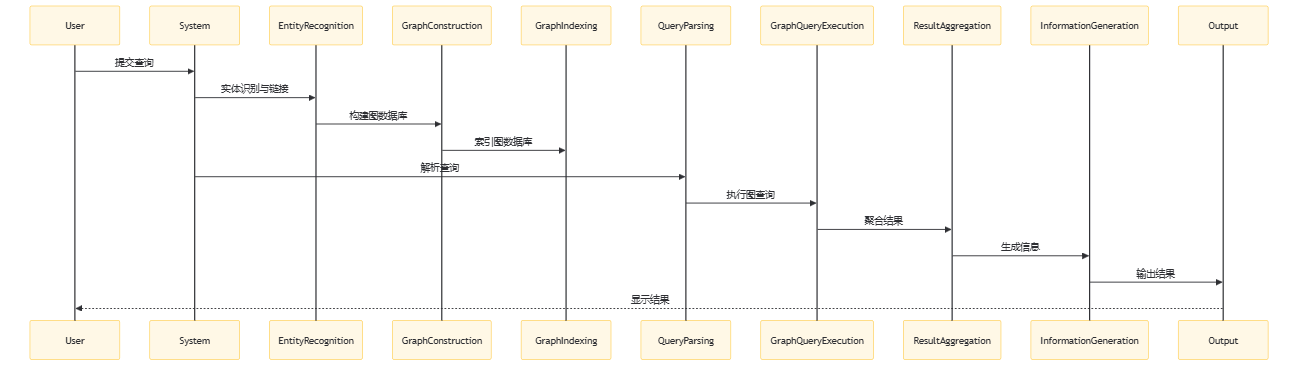
当然, 以下是简化的时序解释:
- User:用户向系统提交查询。
- System:系统接收用户查询, 并开始处理流程。
- EntityRecognition:系统识别查询中的实体。
- GraphConstruction:系统构建包含实体和关系的图数据库。
- GraphIndexing:系统对图数据库进行索引以优化检索。
- QueryParsing:系统解析用户查询以确定检索目标。
- GraphQueryExecution:系统在图数据库中执行查询以检索相关信息。
- ResultAggregation:系统聚合检索结果。
- InformationGeneration:系统根据聚合结果生成回答或完成任务。
- Output:系统将最终结果输出给用户。
语义分析检索
nlp 语义分析是指使用自然语言处理技术来理解用户查询的含义, 并将其转换为可处理的形式。然后, 系统将增强后的查询传递给知识库, 以获取最匹配的知识。
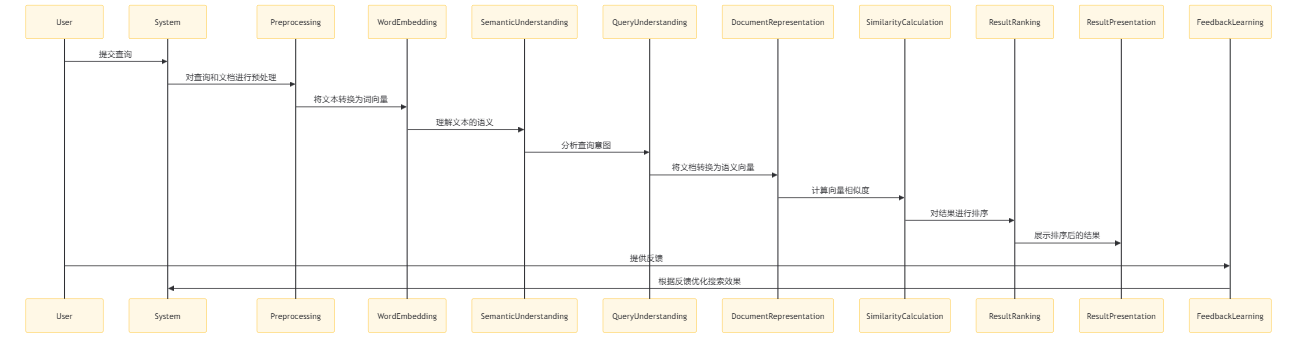
- User:用户向系统提交查询。
- System:系统接收查询并开始处理流程。
- Preprocessing:系统对查询和文档进行预处理, 如分词、去除停用词等。
- WordEmbedding:系统使用词嵌入技术将文本转换为数值向量。
- SemanticUnderstanding:系统利用 NLP 技术理解文本的深层语义。
- QueryUnderstanding:系统分析用户的查询意图, 可能包括查询扩展或重写。
- DocumentRepresentation:系统将文档转换为语义向量, 以便进行语义相似度比较。
- SimilarityCalculation:系统计算查询向量和文档向量之间的相似度。
- ResultRanking:系统根据相似度分数对检索结果进行排序。
- ResultPresentation:系统将排序后的结果呈现给用户。
- FeedbackLearning:用户对结果提供反馈, 系统根据这些反馈进行学习, 以优化未来的搜索效果。
混合搜索
混合搜索是一种将多个检索方法结合在一起的搜索方法。它可以提高搜索结果的质量, 并减少搜索时间。
增强
“增强”(Augmentation)指的是将从外部知识库检索到的信息整合到语言模型的输入中, 以增强模型对特定问题的理解和回答能力。
重排
重排通常涉及到使用机器学习模型来重新计算检索到的上下文的相关性得分, 并根据这些得分对文档进行重新排序。这里我们使用一个简单的假设模型来演示重排的过程:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 假设我们有以下检索到的文档块
documents = [
"The quick brown fox jumps over the lazy dog",
"The lazy dog sleeps in the sun",
"The quick brown fox is very quick"
]
# 用户查询
query = "quick brown fox"
# 使用TF-IDF向量化查询和文档
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents + [query])
# 计算查询向量与每个文档向量之间的余弦相似度
query_vector = tfidf_matrix[-1:]
doc_vectors = tfidf_matrix[:-1]
cosine_sim_scores = cosine_similarity(query_vector, doc_vectors).flatten()
# 根据相关性得分对文档进行排序
sorted_indices = cosine_sim_scores.argsort()[::-1]
sorted_documents = [documents[i] for i in sorted_indices]
# 输出重排后的文档
print("Re-ranked documents based on relevance:")
for doc in sorted_documents:
print(doc)
提示压缩
提示压缩涉及到从检索到的文档块中提取关键信息, 并减少无关上下文。这里我们使用一个简单的摘要方法来演示提示压缩的过程:
from transformers import pipeline
# 假设我们有以下检索到的文档块
documents = [
"The quick brown fox jumps over the lazy dog",
"The lazy dog sleeps in the sun",
"The quick brown fox is very quick"
]
# 使用Hugging Face的摘要模型进行提示压缩
summarizer = pipeline("summarization")
# 对每个文档块进行摘要
summarized_documents = []
for doc in documents:
summary = summarizer(doc, max_length=50, min_length=25, do_sample=False)
summarized_documents.append(summary[0]['summary_text'])
# 输出压缩后的文档
print("Summarized documents:")
for doc in summarized_documents:
print(doc)
在实际应用中, 重排可能需要更复杂的机器学习模型, 如基于深度学习的排名模型, 而提示压缩可能需要更高级的摘要技术, 如抽取式摘要或基于大型语言模型的生成式摘要。
生成
利用大模型生成回答。将上一步中构建的提示模板输入到 LLM 中, 模型会参考这些信息生成回答。
这个过程可以通过构建 RAG 流水线的链, 将检索器、提示模板和 LLM 连接在一起来实现。
template = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. Question: {question} Context: {context} Answer: """
prompt = ChatPromptTemplate.from_template(template)
# 生成
llm = ChatOllama(model='llama3')
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = "What did the author do growing up?"
response = rag_chain.invoke(query)
print(response)
生成回答时, 大模型是如何参考检索到的信息的?
- 上下文融合:模型将检索到的文档信息作为上下文的一部分, 与用户的查询一起考虑, 以生成回答。
- 信息提取:模型从检索到的文档中提取关键信息, 如事实、数据和论点, 并将这些信息用于回答的生成。
- 语义理解:模型理解检索信息的语义内容, 并将其与用户的查询意图相匹配, 以生成更准确的回答。
- 连贯性维护:模型确保生成的回答与检索到的信息在语义上是连贯的, 并且直接回应用户的查询。
参考文献
- https://zhuanlan.zhihu.com/p/687851153
- https://blog.csdn.net/2401_84033492/article/details/140058931
- https://blog.csdn.net/FrenzyTechAI/article/details/139107248
- https://blog.csdn.net/qq_27590277/article/details/135212045
小尾巴
本篇限于个人理解局限, 先讲这么多, 希望未来我们可以重新把这些概念和漏掉的知识梳理一遍, 比如 transform 这个概念非常重要, 这里没有提到, 希望可以单独写一篇。
有点干, 下次我们找个开源项目跑下。