前戏
过去两年 AI 大火, 向量数据库 milvus 赋能 RAG 向量搜索加速, 这玩意怎么在 k8s 上部署?
milvus
Milvus 构建在 Faiss、HNSW、DiskANN、SCANN 等流行的向量搜索库之上, 专为在包含数百万、数十亿甚至数万亿向量的密集向量数据集上进行相似性搜索而设计。
支持数据分片、流式数据摄取、动态Schema、结合向量和标量数据的搜索、多向量和混合搜索、稀疏向量和其他许多高级功能。
采用共享存储架构, 其计算节点具有存储和计算分解及横向扩展能力。
官方建议使用 Kubernetes 部署 Milvus。
创建集群
本文使用 kind 来部署 k8s 集群。
下载 kind 和 helm
此处省略细节, 具体可参考前文。
一行命令, 创建一个集群
准备配置文件:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 31000 # 将主机 31000 端口映射到容器的 31000 端口
hostPort: 31000
listenAddress: '0.0.0.0' # Optional, defaults to "0.0.0.0"
protocol: tcp # Optional, defaults to tcp
- role: worker
- role: worker
- role: worker
kubeadmConfigPatches:
- |
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
metadata:
name: config
networking:
serviceSubnet: 10.0.0.0/16
imageRepository: registry.aliyuncs.com/google_containers
nodeRegistration:
kubeletExtraArgs:
pod-infra-container-image: registry.aliyuncs.com/google_containers/pause:3.1
- |
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
metadata:
name: config
networking:
serviceSubnet: 10.0.0.0/16
imageRepository: registry.aliyuncs.com/google_containers
用以上配置文件, 执行集群创建命令, 可以得到一个 4 节点的集群:
$ kind create cluster --config cluster.yaml --name milvus-cluster --image kindest/node:v1.25.3
Creating cluster "milvus-cluster" ...
✓ Ensuring node image (kindest/node:v1.25.3) 🖼
✓ Preparing nodes 📦 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-milvus-cluster"
You can now use your cluster with:
kubectl cluster-info --context kind-milvus-cluster
Have a nice day! 👋
$ kubectl get po -n kube-system
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0f822511a237 kindest/node:v1.25.3 "/usr/local/bin/entr…" 3 minutes ago Up 3 minutes milvus-cluster-worker
aac79b39a00e kindest/node:v1.25.3 "/usr/local/bin/entr…" 3 minutes ago Up 3 minutes 0.0.0.0:31000->31000/tcp, 127.0.0.1:37783->6443/tcp milvus-cluster-control-plane
8e0ef49d0396 kindest/node:v1.25.3 "/usr/local/bin/entr…" 3 minutes ago Up 3 minutes milvus-cluster-worker3
1a67a1f15d5e kindest/node:v1.25.3 "/usr/local/bin/entr…" 3 minutes ago Up 3 minutes milvus-cluster-worker2
helm 应用包
https://github.com/zilliztech/milvus-operator/tree/main/charts/milvus-operator
自定义参数
values.yaml: https://github.com/zilliztech/milvus-operator/blob/main/charts/milvus-operator/values.yaml
比较重要的应该是一下几个:
image:
# image.repository -- The image repository whose default is the chart appVersion.
repository: milvusdb/milvus-operator
# image.pullPolicy -- The image pull policy for the controller.
pullPolicy: IfNotPresent
# image.tag -- The image tag whose default is the chart appVersion.
tag: 'v1.1.5'
# installCRDs -- If true, CRD resources will be installed as part of the Helm chart. If enabled, when uninstalling CRD resources will be deleted causing all installed custom resources to be DELETED
installCRDs: true
monitoringEnabled: false
replicaCount: 1
# autoscaling:
# enabled: false
# minReplicas: 1
# maxReplicas: 100
# targetCPUUtilizationPercentage: 80
# # targetMemoryUtilizationPercentage: 80
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 100m
memory: 100Mi
autoscaling 个人感觉还是挺重要的, 请求大的时候, 均衡更多流量负载, 请求小的时候, 进一步降本增效, 官方代码这里注释掉了, 可能有坑, 哈哈。
安装 operator
milvus-operator watch 自定义资源的定义, 用来创建 Milvus 实例。
helm repo add milvus-operator https://zilliztech.github.io/milvus-operator/
helm repo update milvus-operator
helm -n milvus-operator upgrade --install --create-namespace milvus-operator milvus-operator/milvus-operator
由于我们使用的是kind, 也就是k8s in docker, 需要把镜像导入到kind集群中:
$ docker pull milvusdb/milvus-operator:v1.1.4
$ kind load docker-image milvusdb/milvus-operator:v1.1.4 --name milvus-cluster
$ kubectl get po -n milvus-operator
NAME READY STATUS RESTARTS AGE
milvus-operator-549848966d-8pqn6 1/1 Running 0 9m40s
部署 milvus 实例
这里有各种场景下的Milvus CR:
https://github.com/zilliztech/milvus-operator/blob/main/config/samples/
我们使用这个部署测试集群:
kubectl apply -f https://raw.githubusercontent.com/zilliztech/milvus-operator/main/config/samples/milvus_v1alpha1_milvus.yaml
理论上, 你能得到一堆镜像拉取不成功的 pod, 你可以像我这样, 把这些拉去失败的镜像去重列举出来:
$ kubectl get po -oyaml |grep image: | awk -F": " '{print $2}' | sort | uniq -c
40 apachepulsar/pulsar:2.9.5
6 docker.io/milvusdb/etcd:3.5.14-r1
8 minio/minio:RELEASE.2023-03-20T20-16-18Z
需要使用 kind 将这些镜像导入到集群中, 就可以让 milvus-operator运行起来:
$ docker pull apachepulsar/pulsar:2.9.5
$ kind load docker-image apachepulsar/pulsar:2.9.5 --name milvus-cluster
$ docker pull docker.io/milvusdb/etcd:3.5.14-r1
$ kind load docker-image docker.io/milvusdb/etcd:3.5.14-r1 --name milvus-cluster
$ docker pull minio/minio:RELEASE.2023-03-20T20-16-18Z
$ kind load docker-image minio/minio:RELEASE.2023-03-20T20-16-18Z --name milvus-cluster
导入成功后, 执行 kubectl get po还是有拉取失败的pod, 主要是因为是因为我们部署了一个实例, 实例的镜像没有拉取, 问题不大, 我们继续导入镜像:
$ kubectl get po |grep ImagePullBackOff| awk '{print $1}' |xargs -I {} kubectl get po {} -oyaml | grep image:| awk -F": " '{print
$2}' | sort | uniq -c
5 docker.io/milvusdb/milvus-operator:v1.1.4
5 milvusdb/milvus-operator:v1.1.4
10 milvusdb/milvus:v2.4.17
# 上面两个都导入过, 只需要导入下面这个
$ docker pull milvusdb/milvus:v2.4.17
$ kind load docker-image milvusdb/milvus:v2.4.17 --name milvus-cluster
这样的话, milvus 就可以正常启动了。
上面的脚本, 实际部署中可能要加上 namespace 的参数, 例如:
kubectl get po -n your-ns
milvus 实例架构分析
先分析下这个实例有哪些组件:
# cr 正常部署
$ kubectl get milvus
NAME MODE STATUS UPDATED AGE
my-release cluster Healthy True 2d15h
# 无状态计算组件, 用于读写
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
my-release-milvus-datanode 1/1 1 1 24m
my-release-milvus-indexnode 1/1 1 1 24m
my-release-milvus-mixcoord 1/1 1 1 24m
my-release-milvus-proxy 1/1 1 1 24m
my-release-milvus-querynode-0 1/1 1 1 24m
my-release-milvus-querynode-1 0/0 0 0 24m
my-release-milvus-standalone 0/0 0 0 24m
# 有状态存储组件
$ kubectl get sts
NAME READY AGE
my-release-etcd 3/3 2d15h
my-release-minio 4/4 2d15h
my-release-pulsar-bookie 3/3 2d15h
my-release-pulsar-broker 1/1 2d15h
my-release-pulsar-proxy 1/1 2d15h
my-release-pulsar-recovery 1/1 2d15h
my-release-pulsar-zookeeper 3/3 2d15h
上面的注释只是管中窥豹, 下面我们走读下官方文档。
架构图
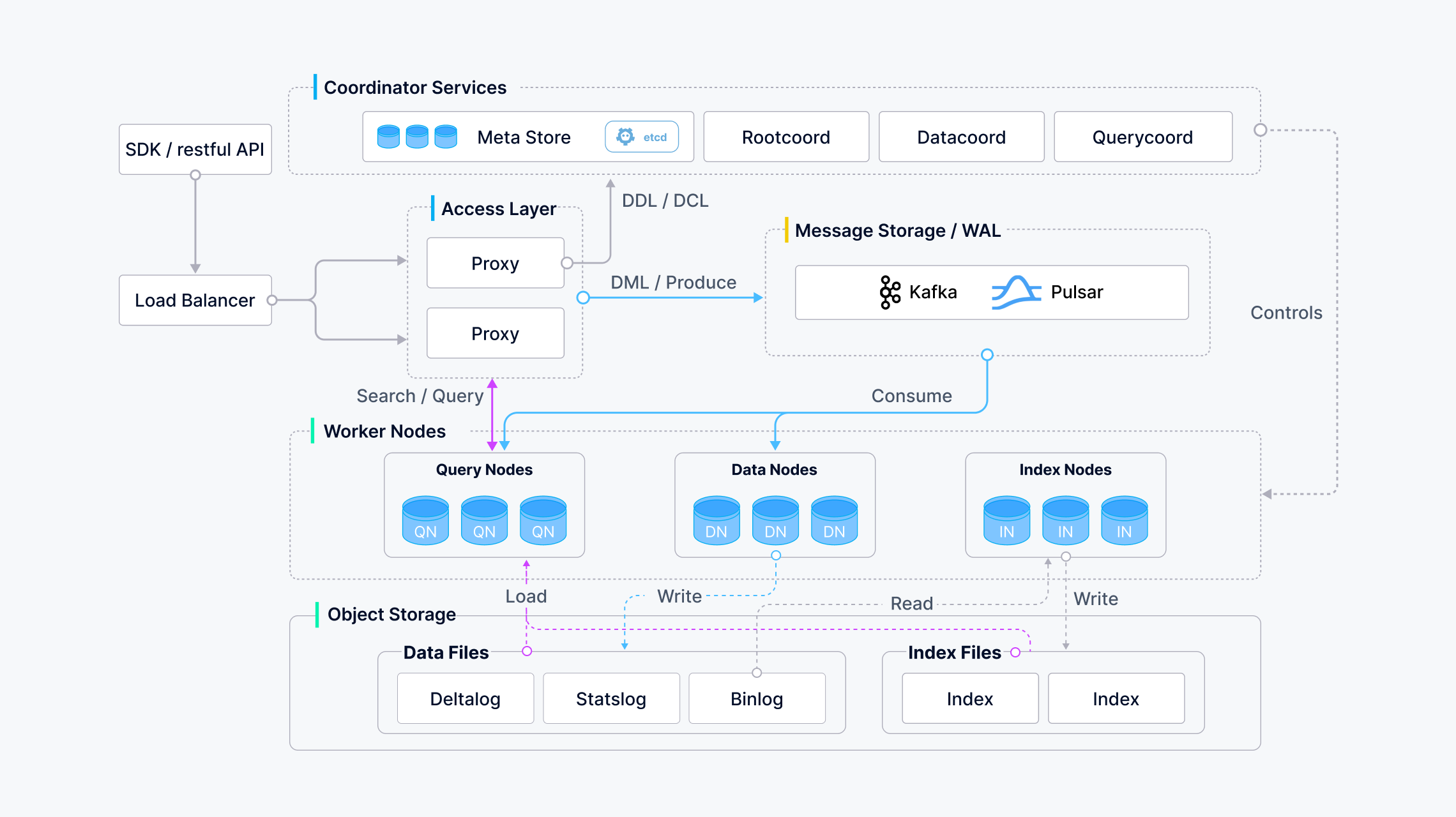
根据该图, 接口可分为以下几类:
- DDL / DCL: createCollection / createPartition / dropCollection / dropPartition / hasCollection / hasPartition
- DML / Produce: 插入 / 删除 / 上移
- DQL: 搜索/查询
交互过程
milvus的设计是存算分离, 具体交互过程如下:
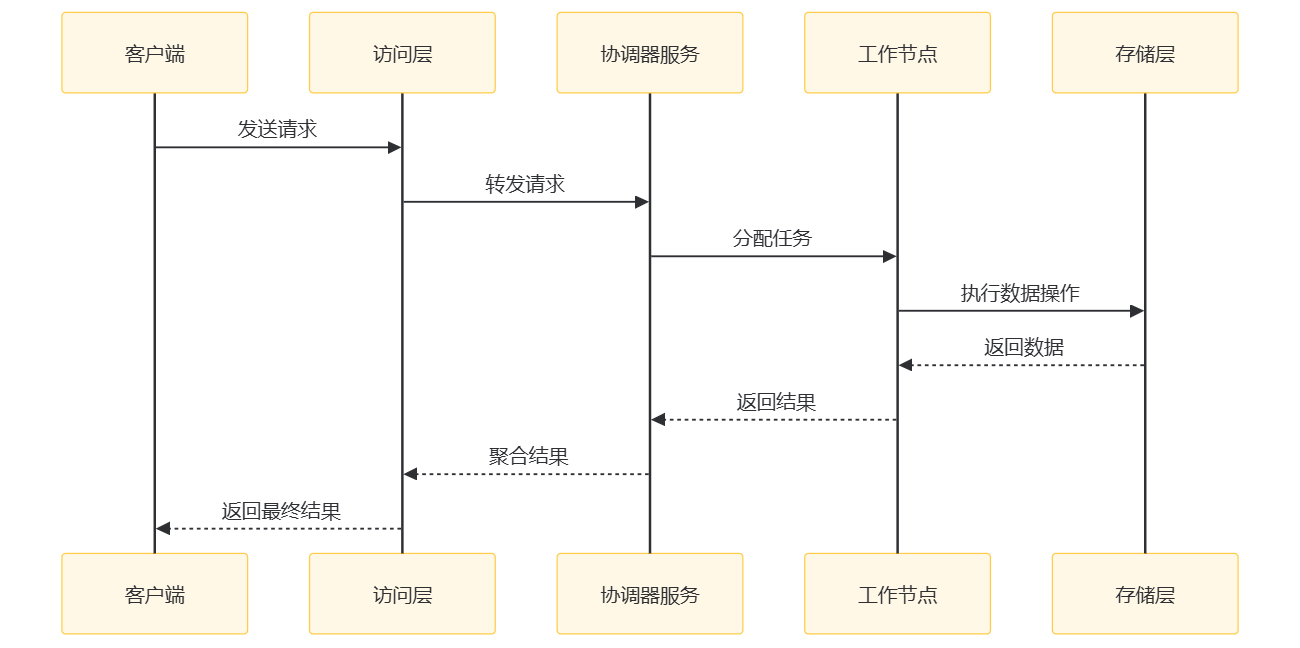
- 客户端: 发起请求, 向 Milvus 系统发起请求。
- 访问层: 作为系统的前端层, 接收客户端请求并转发给协调器服务。同时, 它还负责将协调器服务返回的最终结果返回给客户端。
- 协调器服务: 系统的大脑, 负责任务分配和管理。它接收访问层转发的请求, 将任务分配给工作节点, 并收集工作节点返回的结果, 经过聚合处理后返回给访问层。
- 工作节点: 执行具体的任务, 包括数据操作和索引构建等。它与存储层交互, 执行数据操作并将结果返回给协调器服务。
- 存储层: 负责数据的持久化存储。它接收工作节点的数据操作请求, 执行存储操作, 并将结果返回给工作节点。
在这个系统中, 查询节点负责处理搜索等计算任务, 数据节点负责数据的持久性, 并最终将其存储在 MinIO/S3 等分布式对象存储中。
不知道你有没有注意, 这个系统设计和loki stack有些相似, 它也分为协调服务/查询节点/数据节点/对象存储等, 可能优秀的架构都是差不多的吧, 差异在细节和产品特色上。
存储层
消息存储
Milvus 默认使用 Pulsar 作为消息存储, 还支持Kafka和RocksMQ:
元数据存储
Milvus 使用 etcd 作为元数据存储, 并且计划支持mysql
etcd 支持自建集群inCluster, 和外部集群external:
- external: 改为
true. - endpoints: 提供 etcd 集群地址.
外部etcd配置如下:
apiVersion: milvus.io/v1beta1
kind: Milvus
metadata:
name: my-release
labels:
app: milvus
spec:
dependencies: # Optional
etcd:
external: true
endpoints:
# your etcd endpoints
- 192.168.1.1:2379
对象存储
Milvus 使用 minio 或者s3 保存索引和二进制文件, 与etcd类似, 支持自建集群inCluster, 和外部集群external:
# # change the <parameters> to match your environment
apiVersion: v1
kind: Secret
metadata:
name: my-release-s3-secret
type: Opaque
stringData:
accesskey: <my-access-key>
secretkey: <my-secret-key>
---
# # change the <parameters> to match your environment
apiVersion: milvus.io/v1beta1
kind: Milvus
metadata:
name: my-release
labels:
app: milvus
spec:
# Omit other fields ...
config:
minio:
# your bucket name
bucketName: <my-bucket>
# Optional, config the prefix of the bucket milvus will use
rootPath: milvus/my-release
useSSL: true
dependencies:
storage:
# enable external object storage
external: true
type: S3 # MinIO | S3
# the endpoint of AWS S3
endpoint: s3.amazonaws.com:443
# the secret storing the access key and secret key
secretRef: 'my-release-s3-secret'
一致性
根据CAP理论, 分布式系统在设计和实现时需要在三个关键属性之间做出权衡: 一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance):
- CA(Consistency and Availability): 如果一个系统选择了一致性和可用性, 那么它必须在网络分区发生时牺牲分区容忍性;
- CP(Consistency and Partition tolerance): 如果一个系统选择了一致性和分区容忍性, 那么它在网络分区发生时可能无法保证可用性;
- AP(Availability and Partition tolerance): 如果一个系统选择了可用性和分区容忍性, 那么它在网络分区发生时可能会牺牲一致性;
批处理数据可以理解为已经存储在对象存储中的数据, 而流式数据指的是尚未存储在对象存储中的数据。由于网络延迟, 查询节点通常无法保存最新的流数据。
为了解决这个问题, Milvus 对数据队列中的每条记录都打上时间戳, 并不断向数据队列中插入同步时间戳。每当收到同步时间戳(syncTs), QueryNodes 就会将其设置为服务时间, 这意味着 QueryNodes 可以查看该服务时间之前的所有数据。基于 ServiceTime, Milvus 可以提供保证时间戳(GuaranteeTs), 以满足用户对一致性和可用性的不同要求。
一致性级别具体有以下几种, 以确保每个节点或副本在读写操作期间都能访问相同的数据:
Strong: 使用最新的时间戳作为 GuaranteeTs, 查询节点必须等到服务时间满足 GuaranteeTs 后才能执行搜索请求。
Eventually: GuaranteeTs 设置为极小值(如 1), 以避免一致性检查, 这样查询节点就可以立即对所有批次数据执行搜索请求。
Bounded: GuranteeTs 设置为早于最新时间戳的时间点, 以便查询节点在执行搜索时能容忍一定的数据丢失。
Session: 客户端插入数据的最新时间点被用作 GuaranteeTs, 这样查询节点就能对客户端插入的所有数据执行搜索。
测试集群
通过 ui 测试集群
安装 ui
https://github.com/zilliztech/attu/blob/main/attu-k8s-deploy.yaml
注意这个环境变量:
env:
- name: MILVUS_URL
value: 'my-release-milvus:19530'
$ kubectl apply -f https://raw.githubusercontent.com/zilliztech/attu/refs/heads/main/attu-k8s-deploy.yaml
$ docker pull docker.io/zilliz/attu:v2.4
$ kind load docker-image docker.io/zilliz/attu:v2.4 --name milvus-cluster
暴露 ui
之前我们在
kind配置中保留了31000这个端口, 会将主机上的31000映射到集群 ui 的service
我们把下面这个service暴露成NodePort类型, 这样我们就可以在本地访问集群了:
$ kubectl edit svc my-attu-svc
---
ports:
- name: attu
nodePort: 31000
port: 3000
protocol: TCP
targetPort: 3000
...
type: NodePort
$ curl localhost:31000
登录界面:
创建集合:
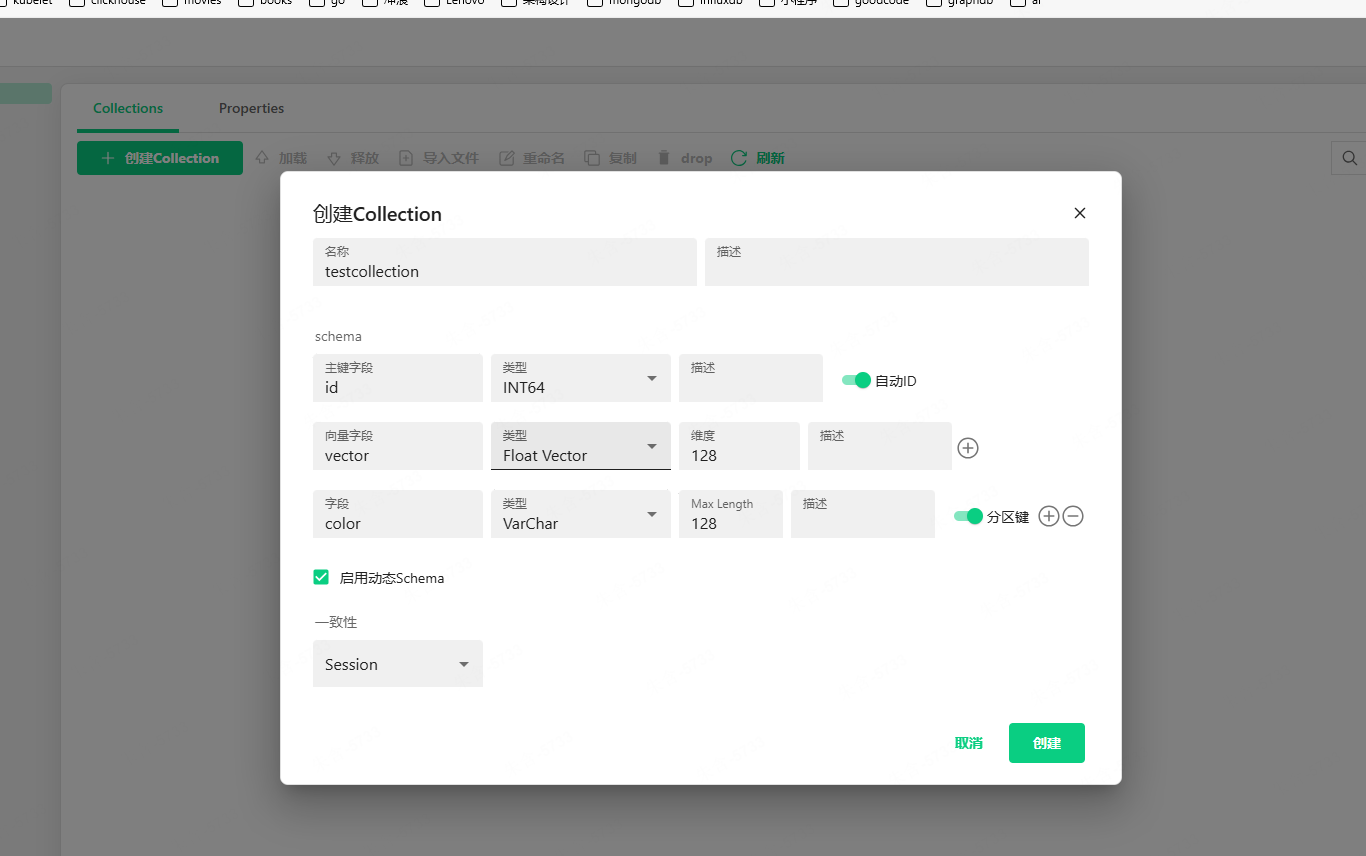
这个自动生成样例数据导入的功能很 nice:
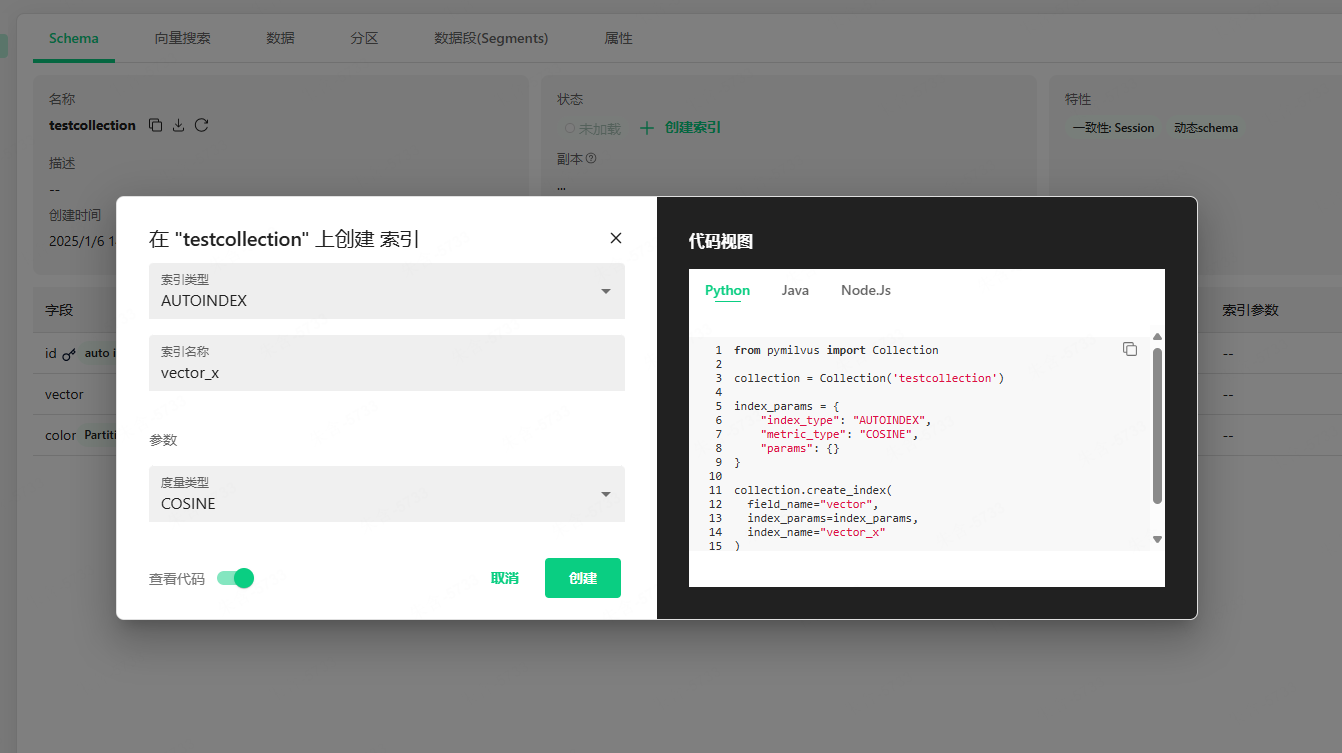
构建一个 cosine 索引:
加载集合:
更多功能, 请自行体验玩耍~
通过暴露实例 service 访问集群
修改 milvus 服务类型
$ kubectl edit milvus
proxy:
paused: false
replicas: 1
serviceType: NodePort
$ curl localhost:31000
看了下源码似乎不支持自定义nodePort为31000, 如果手动修改 service, 发现很快就被operator 调协回去了, 只能随机选择:
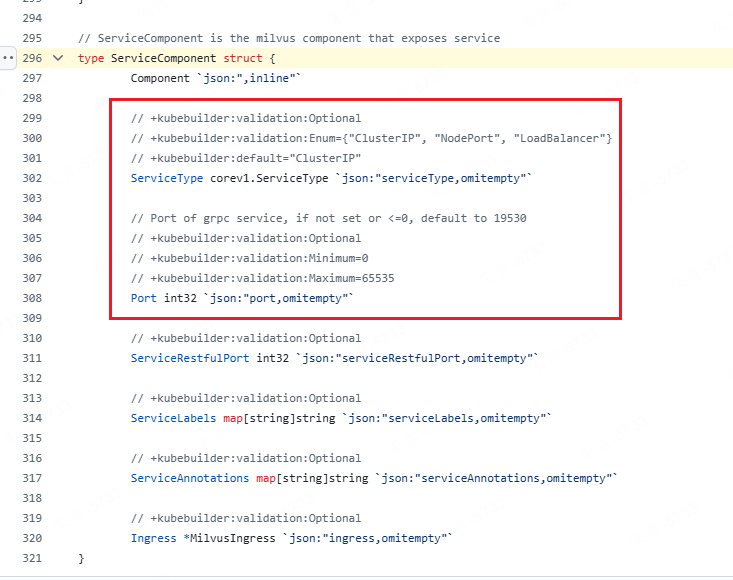
哈哈哈, 如果还是想 diy, 那就把operator停止调协, 然后再操作即可, 不建议这么做:
$ kubectl -n milvus-operator scale deploy/milvus-operator --replicas=0
$ kubectl edit service my-release-milvus
还是按照规范来, 直接port-forward:
$ kubectl port-forward service/my-release-milvus 19530:19530 --address 0.0.0.0
测试 Milvus
通过 python 来和milvus 交互, 需要使用下面这个包:
pip install pymilvus
完整脚本:
>>> from pymilvus import MilvusClient, DataType
# 访问test数据库
>>> client = MilvusClient(uri="http://localhost:19530/test")
>>> client.list_collections()
['testcollection']
>>> client.describe_collection("testcollection")
{'collection_name': 'testcollection', 'auto_id': True, 'num_shards': 1, 'description': '', 'fields': [{'field_id': 100, 'name': 'id', 'description': '', 'type': <DataType.INT64: 5>, 'params': {}, 'auto_id': True, 'is_primary': True}, {'field_id': 101, 'name': 'vector', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 128}}, {'field_id': 102, 'name': 'color', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 128}, 'is_partition_key': True}], 'functions': [], 'aliases': [], 'collection_id': 455116632365614380, 'consistency_level': 1, 'properties': {}, 'num_partitions': 16, 'enable_dynamic_field': True}
>>> client.get(collection_name="testcollection",ids=[455116632364191056],output_fields=["color"])
执行上面的脚本, 需要你在 test 数据库中创建一个名为 testcollection 的集合, 并且在集合中插入一些数据, 并保证有一些数据和索引, 并进行了数据加载, 你可以在 ui 部分操作这一步骤
小尾巴
这章有点干, 后面我们继续研究 milvus 的查询和搜索, 求关注~