前戏
今天我们用 DeepSearcher 体验下 Deep Research 的强大功能。
🌟 Deep-Searcher
DeepSearcher 是一个开源的深度搜索工具, 旨在通过结合强大的语言模型(如 OpenAI、DeepSeek 等)和向量数据库, 在私有数据上进行高效搜索、评估和推理, 提供高精度的答案和综合报告。
🚀 功能特点
- 🔍 私有数据搜索:最大化利用企业内部数据, 同时确保数据安全。必要时可整合在线内容以提供更准确的答案。
- 📊 向量数据库管理:支持 Milvus 等向量数据库, 允许数据分区以提高检索效率。
- 🎨 灵活的嵌入选项:兼容多种嵌入模型, 可选择最优方案。
- 🌐 多语言模型支持:支持多种大型语言模型(LLM), 如 DeepSeek、OpenAI、Anthropic Claude、Google Gemini 等。
- 📄 文档加载器:支持本地文件加载(如 PDF、TXT 等), 并正在开发网页爬取功能。
- 🔗 RESTful API 接口:提供 API 接口, 方便与其他系统集成。
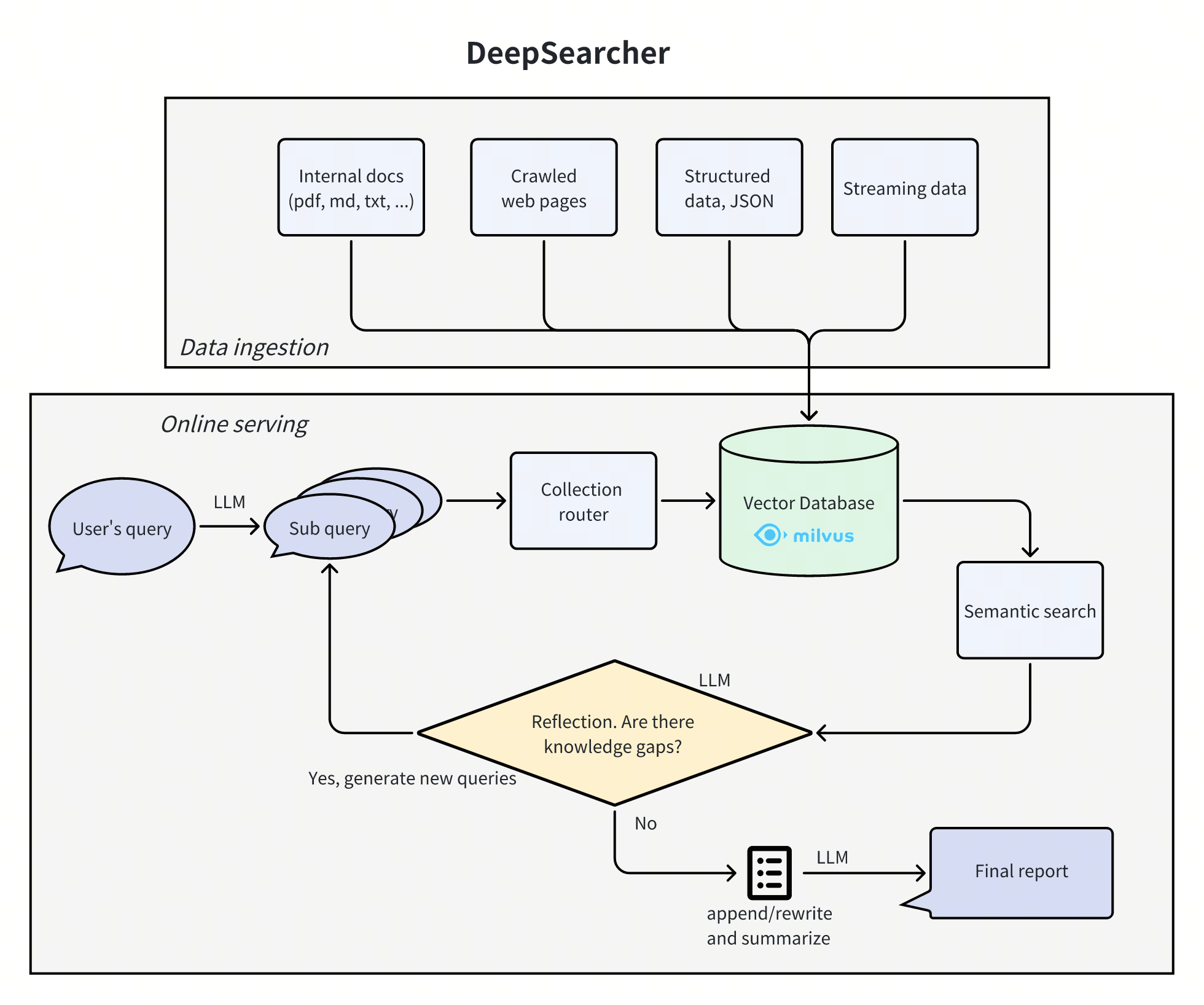
架构设计和代码结构
架构图如下:
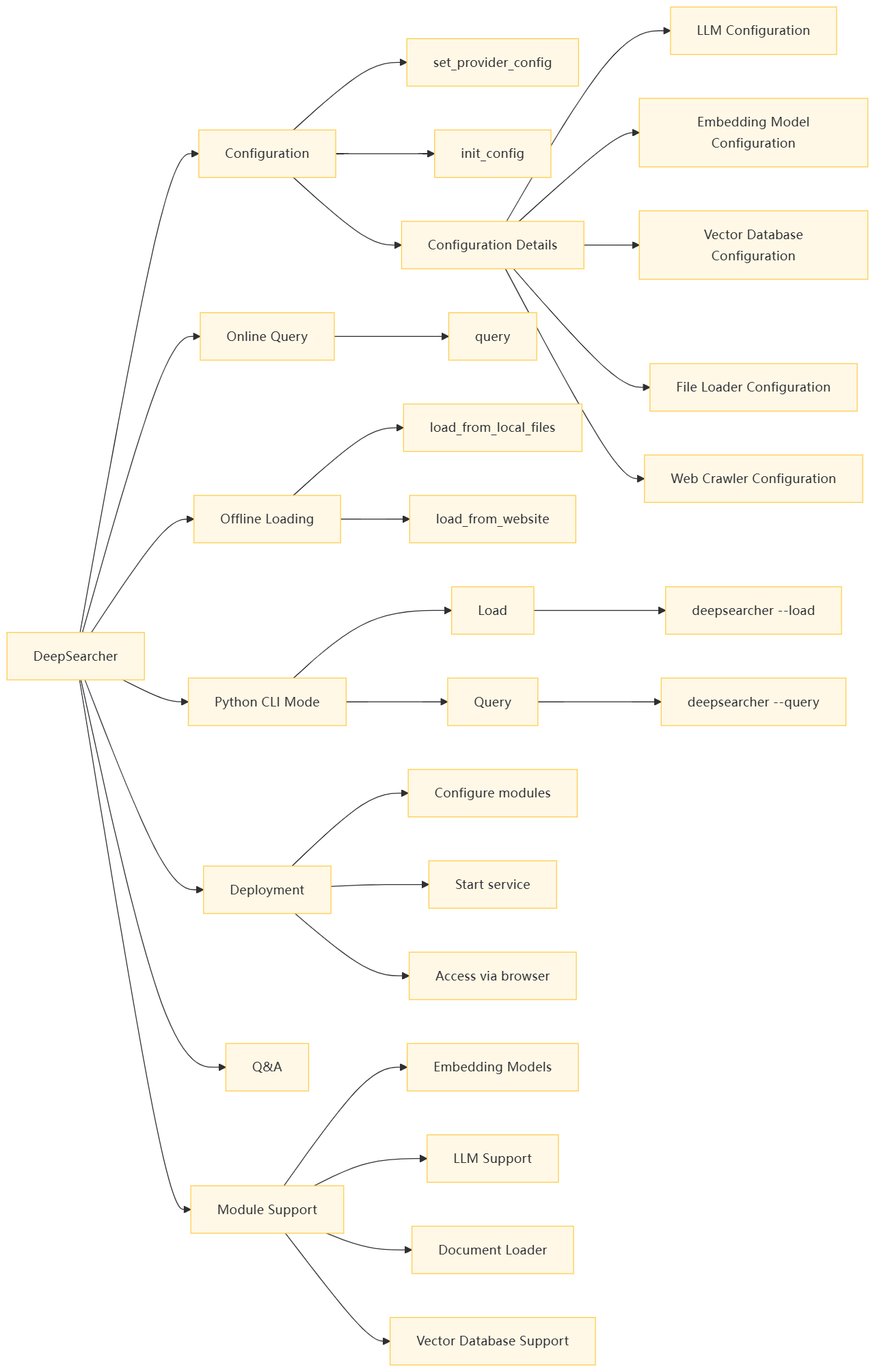
代码结构分析:
📖 快速开始
准备
下载代码, 创建 Python 虚拟环境(推荐 Python 版本 >= 3.10) :
git clone https://github.com/zilliztech/deep-searcher.git
cd deep-searcher
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
快速使用
部署 filecrawl [可选]
filecrawl 并不是完全免费的, 这里我们采用自建的方法:
git clone https://github.com/mendableai/firecrawl
cd firecrawl
docker-compose up -d
下载 deep-reseacher 源码
这里我们使用最新版, 支持 ollama
"""
git clone https://github.com/zilliztech/deep-searcher.git
"""
from deepsearcher.configuration import Configuration, init_config
from deepsearcher.online_query import query
# https://milvus.io/docs/embeddings.md
# pip install pymilvus[model]
config = Configuration()
# Customize your config here,
# more configuration see the Configuration Details section below.
config.set_provider_config("llm", "Ollama", {"model": "deepseek-r1:7b", "base_url": "http://192.168.137.13:11434"})
config.set_provider_config("vector_db", "Milvus", {"uri": "./milvus.db", "token": ""})
config.set_provider_config("embedding", "MilvusEmbedding", {"model": "default"})
config.set_provider_config("web_crawler", "JinaCrawler", {})
init_config(config=config)
# Load your local data
# from deepsearcher.offline_loading import load_from_local_files
# load_from_local_files(paths_or_directory=your_local_path)
# (Optional) Load from web crawling (`FIRECRAWL_API_KEY` env variable required)
from deepsearcher.offline_loading import load_from_website
load_from_website(urls="https://milvus.io/zh/blog/introduce-deepsearcher-a-local-open-source-deep-research.md")
# Query
result = query("Write a report about deep research") # Your question here
运行以上代码, 可能会有点问题, 因为 deepseek 的回答有 think 和加粗的格式问题, 需要从最后一行提取选择的 agent id
需要在源码稍作改造, 抛砖引玉, 下面是一个粗稿代码:
agent/rag_router.py
def _route(self, query: str) -> Tuple[RAGAgent, int]:
description_str = "\n".join(
[f"[{i + 1}]: {description}" for i, description in enumerate(self.agent_descriptions)]
)
prompt = RAG_ROUTER_PROMPT.format(query=query, description_str=description_str)
chat_response = self.llm.chat(messages=[{"role": "user", "content": prompt}])
def _parse_agent_index(s: str):
agent = 1
digits = []
for text in s.strip().splitlines()[-1]:
if text.isdigit():
digits.append(text)
elif len(text) > 0:
break
if len(digits) > 0:
agent = int("".join(digits))
return agent
selected_agent_index = int(_parse_agent_index(chat_response.content)) - 1
selected_agent = self.rag_agents[selected_agent_index]
log.color_print(
f"<think> Select agent [{selected_agent.__class__.__name__}] to answer the query [{query}] </think>\n"
)
return self.rag_agents[selected_agent_index], chat_response.total_tokens
输出如下, 有点慢:
<think> Select agent [DeepSearch] to answer the query [Write a report about deep research] </think>
<query> Write a report about deep research </query>
<think> Break down the original query into new sub queries: ['What is deep research?', 'Why is deep research important?', 'How can deep research be effectively performed?', 'Can you provide an example of deep research?']</think>
>> Iteration: 1
<think> Perform search [Why is deep research important?] on the vector DB collections: ['deepsearcher'] </think>
<search> Search [Why is deep research important?] in [deepsearcher]... </search>
<think> Perform search [How can deep research be effectively performed?] on the vector DB collections: ['deepsearcher'] </think>
<search> Search [How can deep research be effectively performed?] in [deepsearcher]... </search>
....
其他配置
# embedding:
config.set_provider_config("embedding", "OpenAIEmbedding", {"model": "text-embedding-ada-002"})
# 向量数据库:
config.set_provider_config("vector_db", "Milvus", {"uri": "./milvus.db", "token": ""})
# 文件加载器:
config.set_provider_config("file_loader", "PDFLoader", {})
# 网络爬虫
config.set_provider_config("web_crawler", "FireCrawlCrawler", {})
# 大模型
config.set_provider_config("llm", "DeepSeek", {"model": "deepseek-chat"})
📚 client 客户端
deepsearcher –query “Write a report about xxx.”
小尾巴
今天我们一起跑了 deepseek + ollama + deep-searcher 的实践过程, 希望会对你有所帮助!