前戏
小白: 老花, 我今天想了解下 golang 的对象复用是干啥用的?
老花: 对象复用, 顾名思义, 就是把对象进行复用, 而不是每次都重新创建一个对象, 这样可以减少内存的开销, 提高性能, 减少 GC 的次数。
对象复用如何使用?
golang的对象复用主要是要sync.Pool实现, 它是并发安全的对象池。
首先, 声明对象池, 需要提供一个对象的构造函数 New:
var pool = sync.Pool{
New: func() interface{} {
return new(MyType) // MyType 是你想要复用的对象类型
},
}
当从对象池中获取对象时,如果池中没有可用对象,会调用 New 函数创建一个新的对象。
使用 Get 方法从对象池中获取对象,使用 Put 方法将对象放回对象池。
obj := pool.Get().(*MyType)
pool.Put(obj)
不过项目中, 我们都会简单地进行封装使用:
var dataPool sync.Pool
type UserData struct {
Data []byte
Key string
}
func GetUserData() *UserData {
si := dataPool.Get()
if si == nil {
return &UserData{}
}
return si.(*UserData)
}
func PutUserData(si *UserData) {
if si == nil {
return
}
dataPool.Put(si)
}
这样, 我们只需要使用GetUserData 和 PutUserData 就可以了。
对象复用怎么实现的?
sync.Pool是一个并发安全的对象池,它内部维护了一个链表,用于存储对象。
当需要获取对象时,会从链表中取出一个对象,如果链表为空,则调用New函数创建一个新的对象。当对象不再使用时,需要我们主动调用Put函数将对象放回对象池。
结构体定义
// In the terminology of the Go memory model, a call to Put(x) “synchronizes before”
// a call to Get returning that same value x.
// Similarly, a call to New returning x “synchronizes before”
// a call to Get returning that same value x.
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() any
}
sync.Pool结构体包含以下字段:
local:指向一个固定大小的本地池数组,每个逻辑处理器(P)都有一个本地池。localSize:本地池数组的大小。victim:指向上一个循环的本地池,用于存储不再被当前本地池使用的元素。victimSize:上一个循环的本地池的大小。New:一个可选的函数,当 Get 方法返回 nil 时,会调用这个函数来生成一个新的值。
核心方法:
- Put(x any):将对象 x 放回池中。
- Get() any:从池中获取一个对象,如果池为空,则可能返回 nil 或调用 New 函数生成一个新的对象。
工作原理
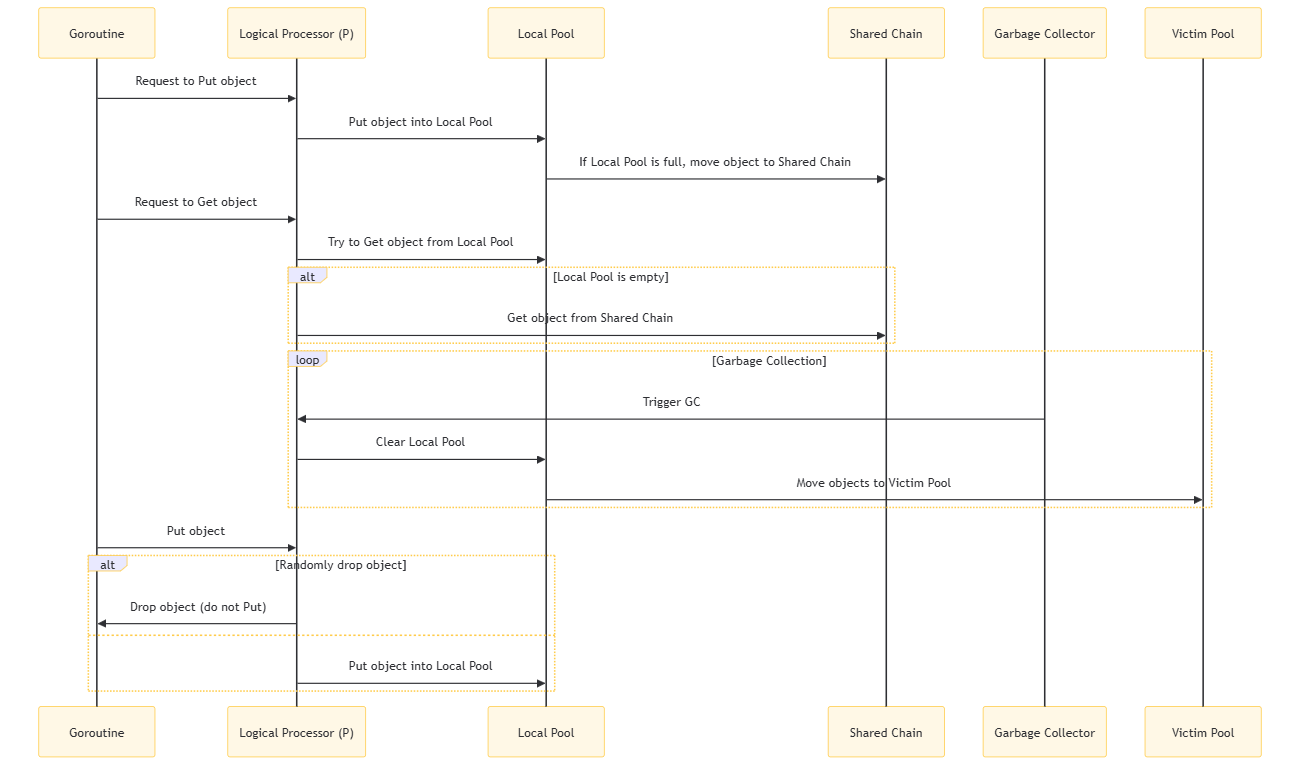
在这个时序图中,我们可以看到以下步骤:
- 一个 goroutine 请求将对象放入 sync.Pool。
- 逻辑处理器(P)将对象放入本地池(LP)。
- 如果本地池满了,对象被移动到共享链(SC)争抢一个。
- 当 goroutine 请求从 sync.Pool 获取对象时,逻辑处理器尝试从本地池获取对象。
- 如果本地池为空,则从共享链获取对象。
- 在垃圾收集过程中,垃圾收集器(GC)触发清理,逻辑处理器清除本地池,并将对象移动到受害者池(VP)。
- 当
goroutine请求将对象放回sync.Pool时,逻辑处理器有一定概率随机丢弃对象,或者将对象放回本地池。
通过这种设计方式, sync.Pool 有效减少了锁冲突, 减少了 GC 的次数, 提高了性能。但是, 缺点也很明显:
- 对象的数量不可控
- 对象的生命周期不可控
- 对象不被回收时, 可能导致内存占用过高
- 存在大对象给小对象复用浪费的情况
如何解决对象不可控?
对象分配计数器
维护一个原子计数器, 创建对象, 则计数增加 1, 释放对象, 则计数减少, 当这个计数器超过阈值, 不再分配对象, 可以返回报错或者阻塞获取对象。(报错可能体验不太好, 哈哈…)
package main
import (
"atomic"
"errors"
"fmt"
"sync"
)
var (
ErrLimitExceeded = errors.New("object allocation limit exceeded")
)
type ObjectPool struct {
pool sync.Pool
limit int64 // 分配对象的最大限制
count int64 // 当前分配的对象数量
factory func() interface{} // 对象工厂函数
}
func NewObjectPool(factory func() interface{}, limit int64) *ObjectPool {
return &ObjectPool{
factory: factory,
limit: limit,
}
}
// Get 获取一个对象,如果超过限制则返回错误
func (p *ObjectPool) Get() (interface{}, error) {
if atomic.LoadInt64(&p.count) >= p.limit {
return nil, ErrLimitExceeded
}
obj := p.pool.Get()
if obj == nil {
// 如果池中没有对象,则使用工厂函数创建新对象
obj = p.factory()
}
// 增加计数
atomic.AddInt64(&p.count, 1)
return obj, nil
}
// Put 释放一个对象,减少计数
func (p *ObjectPool) Put(obj interface{}) {
// 减少计数
atomic.AddInt64(&p.count, -1)
// 将对象放回池中
p.pool.Put(obj)
}
使用 channel
使用一个 channel 来控制对象的数量, 当 channel 满时, 不再分配对象, 可以返回报错或者阻塞获取对象。
package main
import (
"bufio"
"fmt"
"os"
"time"
)
// ObjectPool 使用 channel 控制对象的数量
type ObjectPool struct {
factory func() interface{} // 对象工厂函数
ch chan struct{} // 控制对象数量的 channel
}
// NewObjectPool 创建一个新的 ObjectPool 实例
func NewObjectPool(factory func() interface{}, limit int) *ObjectPool {
return &ObjectPool{
factory: factory,
ch: make(chan struct{}, limit), // 创建一个有缓冲的 channel,缓冲大小为
}
}
// Get 获取一个对象,如果 channel 满则阻塞等待
func (p *ObjectPool) Get() interface{} {
<-p.ch
obj := p.factory() // 使用工厂函数创建新对象
return obj
}
// Put 释放一个对象,将值放回 channel
func (p *ObjectPool) Put(obj interface{}) {
// 将对象的状态重置,以便复用
// obj == nil 表示对象已经被释放,不需要重置
p.ch <- struct{}{}
}
开源实现
老花这里找了一个star不错的开源项目https://github.com/jolestar/go-commons-pool:
import (
"context"
"fmt"
"strconv"
"sync/atomic"
"github.com/jolestar/go-commons-pool/v2"
)
func Example_simple() {
type myPoolObject struct {
s string
}
v := uint64(0)
factory := pool.NewPooledObjectFactorySimple(
func(context.Context) (interface{}, error) {
return &myPoolObject{
s: strconv.FormatUint(atomic.AddUint64(&v, 1), 10),
},
nil
})
ctx := context.Background()
p := pool.NewObjectPoolWithDefaultConfig(ctx, factory)
obj, err := p.BorrowObject(ctx)
if err != nil {
panic(err)
}
o := obj.(*myPoolObject)
fmt.Println(o.s)
err = p.ReturnObject(ctx, obj)
if err != nil {
panic(err)
}
// Output: 1
}
benchmark 如下:
func BenchmarkPoolBorrowReturnParallel(b *testing.B) {
ctx := context.Background()
pool := NewObjectPoolWithDefaultConfig(ctx, NewPooledObjectFactorySimple(func(context.Context) (interface{}, error) {
return &BenchObject{}, nil
}))
pool.Config.MaxTotal = 100
defer pool.Close(ctx)
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
o, err := pool.BorrowObject(ctx)
//fmt.Println("borrow:",reflect.ValueOf(o).Pointer())
if err != nil {
fmt.Println(err)
b.Fail()
}
err = pool.ReturnObject(ctx, o)
//fmt.Println("return:",reflect.ValueOf(o).Pointer())
if err != nil {
fmt.Println(err)
b.Fail()
}
}
})
}
如何解决对象复用浪费?
对对象的大小进行分类, 不同的对象大小使用不同的池:
var msg1MPool, msg10MPool, msg16MPool, msg20MPool, msg24MPool sync.Pool
type userData struct {
Body []byte
}
const (
defaultSize1M = 1 << 20
defaultSize10M = 10 << 20
defaultSize16M = 16 << 20
defaultSize20M = 20 << 20
defaultSize24M = 24 << 20
)
func getLevel(size int64) int {
if size > defaultSize24M {
return -1
} else if size <= defaultSize24M && size > defaultSize20M {
return 0
} else if size <= defaultSize20M && size > defaultSize16M {
return 1
} else if size <= defaultSize16M && size > defaultSize10M {
return 2
} else if size <= defaultSize10M && size > defaultSize1M {
return 3
} else {
return 4
}
}
func Acquire(size int64) *userData {
var v interface{}
level := getLevel(size)
switch level {
case -1:
return &userData{Body: bytes.NewBuffer(make([]byte, 0, size))}
case 0:
v = msg24MPool.Get()
if v == nil {
return &userData{Body: bytes.NewBuffer(make([]byte, 0, defaultSize24M))}
}
case 1:
v = msg20MPool.Get()
if v == nil {
return &userData{Body: bytes.NewBuffer(make([]byte, 0, defaultSize20M))}
}
case 2:
v = msg16MPool.Get()
if v == nil {
return &userData{Body: bytes.NewBuffer(make([]byte, 0, defaultSize16M))}
}
case 3:
v = msg10MPool.Get()
if v == nil {
return &userData{Body: bytes.NewBuffer(make([]byte, 0, defaultSize10M))}
}
case 4:
v = msg1MPool.Get()
if v == nil {
return &userData{Body: bytes.NewBuffer(make([]byte, 0, defaultSize1M))}
}
}
b := v.(*userData)
if b.Body.Cap() < int(size) {
return &userData{Body: bytes.NewBuffer(make([]byte, 0, size))}
}
return b
}
func Release(b *userData) {
if b == nil {
return
}
level := getLevel(int64(b.Body.Cap()))
b.Name = ""
b.Body.Reset()
switch level {
case 0:
msg24MPool.Put(b)
case 1:
msg20MPool.Put(b)
case 2:
msg16MPool.Put(b)
case 3:
msg10MPool.Put(b)
case 4:
msg1MPool.Put(b)
}
}
以上代码仅供参考, 具体实现需要根据实际情况进行修改!
小尾巴
老花: 对象复用虽然不可控, 但是对提升程序性能还是有很大优势的, 赶快使用起来吧! 在实际的项目中, 你可能要根据bodySize大小来分割多个对象复用的pool, 这样不至于产生大对象给小对象复用而浪费的情况!