前戏
小白: 老花, 我想学习下
golang如何批量写入和消费 kafka?
老花: 可以的, 我这里要推荐一个golang的kafka库, github.com/segmentio/kafka-go, 在此之前, 我们先来一波八股文。
kafka 分区架构(八股文)
分区
分区(Partition)是 Kafka 中最基本的数据存储单元。每个主题(Topic)可以有多个分区, 每个分区都是一个有序的、不可变的消息序列。分区的设计使得 Kafka 能够实现数据的并行处理和负载均衡。
- 并行处理: 通过分区, Kafka 允许多个消费者并行处理不同分区的数据, 从而提高系统的处理能力。
- 数据本地性: 每个分区可以分布在不同的 Broker 上, 这样可以充分利用集群的存储能力, 并实现数据的分布式存储。
- 顺序保证: 在单个分区内, 消息是有序的, 这有助于确保一些需要顺序处理的场景, 如日志记录。
生产者与消费者操作分区
- 生产者发送消息到指定 Partition: 生产者可以根据需要将消息发送到特定的分区, 这可以通过指定消息的分区键来实现。
- 消费者订阅指定 Partition: 消费者可以选择订阅特定的分区, 也可以订阅整个 Topic, 以实现对特定数据流的处理。
负载均衡
Kafka 的生产者在将消息发送到分区时, 使用分区键的哈希函数来决定消息应该被分配到哪个分区, 这有助于实现负载均衡。
幂等性
enable.idempotence 被设置成 true 后, Producer 自动升级成幂等性, 在底层设计架构中引入了 ProducerID 和 SequenceNumber, 自动帮你做消息的重复去重。
事务
事务要求消息一起成功发送, 要么一起失败。简单来说,就像是个打包操作,把消息 Record1 和 Record2 看作一个整体,要么一起成功,要么一起失败。
然而即使发送失败了, Kafka 也会把消息保存起来, 消费者还是能看到这些消息。
因此,对于消费者来说,读取事务型发送者的消息需要调整isolation.level的设置。
read_uncommitted:这是默认的设置,意味着消费者可以看到 Kafka 里的所有消息,不管这些消息是不是由事务型发送者成功提交的。 如果你用了事务型发送者,那么消费者就不应该用这个设置了。read_committed:这个设置意味着消费者只会看到事务型发送者成功提交的消息。 同时,消费者也能看到那些非事务型发送者发送的所有消息。
优缺点分析
优点:
github.com/segmentio/kafka-go是一个纯Go语言实现的Kafka客户端库, 由Segment.io提供, 不需要使用cgo。- 简洁易用和灵活性而著称, 支持
context, 这很go。
缺点:
- 支持 Kafka 的核心功能, 但在高级功能支持方面可能不如某些其他库, 比如事物, 生产者精准一次配置等。
使用场景分析
- 使用
kafka-go作为消费者从Kafka消费消息, 可以手动控制消息的偏移量提交, 确保消息处理的可靠性。 - 在微服务架构中, 使用
kafka-go作为生产者将事件或日志消息发布到Kafka, 实现服务间的异步通信。 - 在需要动态调整并发处理能力的场景下,
kafka-go可以灵活地调整协程数量, 以适应不同的处理需求。
代码示例
导入依赖: go get github.com/segmentio/kafka-go
生产者端代码
dialer := &kafka.Dialer{
Timeout: 10 * time.Second,
DualStack: true,
TLS: &tls.Config{...tls config...},
}
w := kafka.Writer{
Addr: kafka.TCP("localhost:9092", "localhost:9093", "localhost:9094"),
Topic: "topic-A",
Balancer: &kafka.Hash{},
Dialer: dialer,
}
消费者端代码
dialer := &kafka.Dialer{
Timeout: 10 * time.Second,
DualStack: true,
TLS: &tls.Config{...tls config...},
}
r := kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},
GroupID: "consumer-group-id",
Topic: "topic-A",
Dialer: dialer,
})
sasl 支持
mechanism := plain.Mechanism{
Username: "username",
Password: "password",
}
mechanism, err := scram.Mechanism(scram.SHA512, "username", "password")
if err != nil {
panic(err)
}
dialer := &kafka.Dialer{
Timeout: 10 * time.Second,
DualStack: true,
SASLMechanism: mechanism,
}
conn, err := dialer.DialContext(ctx, "tcp", "localhost:9093")
支持手动 commit
func consumeWithFetchMessage() {
ctx := context.Background()
for {
// 从 Kafka 中获取下一条消息
m, err := kafkaReader.FetchMessage(ctx)
if err != nil {
log.Printf("获取消息时出错: %v", err)
break
}
// 打印消息内容
log.Printf("消息: %s, 偏移量: %d", string(m.Value), m.Offset)
// 处理消息 (在这里可以进行你的业务逻辑)
// 手动提交偏移量
if err := kafkaReader.CommitMessages(ctx, m); err != nil {
log.Printf("提交偏移量时出错: %v", err)
}
}
}
配置
生产者配置
writerConfig := kafka.WriterConfig{
Brokers: kc.Brokers,
BatchSize: kc.BatchSize,
BatchBytes: kc.BatchBytes,
BatchTimeout: kc.BatchTimeout,
MaxAttempts: kc.MaxRetryTimes,
WriteTimeout: kc.WriteTimeout,
RequiredAcks: kc.RequiredAcks,
}
这里的BatchSize和BatchTimeout是控制批量写入的参数, 对于提高写入吞吐非常有用。对应于batch.size和 linger.ms, 配合起来使用的, 目的就是缓存更多的数据, 减少客户端发起请求的次数。这两个参数根据实际情况调整。
BatchBytes是最大可写入的数据量, 默认是 1048576 字节(1MB)。
RequiredAcks是生产者要求写入分片副本返回成功的副本数目, 默认是-1, 如果这个值 X 超过 0, 表示至少要求 X 个副本返回成功。
消费者配置
readConfig := kafka.ReaderConfig{
Topic: topic,
Brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},
GroupID: "consumer-group-id",
StartOffset: kc.StartOffset,
QueueCapacity: kc.QueueCapacity,
MinBytes: kc.MinM * 1024 * 1024,
MaxBytes: kc.MaxM * 1024 * 1024,
MaxWait: time.Duration(kc.MaxWaitMs) * time.Millisecond,
CommitInterval: time.Duration(kc.CommitIntervalSec) * time.Second,
HeartbeatInterval: time.Duration(kc.HeartbeatInterval) * time.Second,
SessionTimeout: time.Duration(kc.SessionTimeoutSec) * time.Second,
RebalanceTimeout: time.Duration(kc.RebalanceTimeoutSec) * time.Second,
JoinGroupBackoff: time.Duration(kc.JoinGroupBackoffSec) * time.Second,
RetentionTime: time.Duration(kc.RetentionTimeSec) * time.Second,
MaxAttempts: kc.MaxAttempts,
OffsetOutOfRangeError: kc.OffsetOutOfRangeError,
}
支持指定 offset 消费StartOffset和配置再平衡时间RebalanceTimeout等配置, 这对于确保消息处理的可靠性非常有用。
精准一次
很遗憾, github.com/segmentio/kafka-go不支持幂等和事务配置, 要实现精准一次消费, 我们需要额外确保每条消息只被处理一次, 并且处理成功后再提交偏移量。
手动提交 offset
接下来, 我们需要从 Kafka 消费消息, 并在处理成功后提交偏移量。为了确保精准一次消费, 我们可以在消息处理成功后立即提交偏移量。
func consumeAndProcess(consumer *kafka.Reader) {
for {
msg, err := consumer.ReadMessage(context.Background())
if err != nil {
log.Fatal("failed to read message:", err)
}
// 处理消息
processMessage(msg)
// 提交偏移量
if err := consumer.CommitMessages(context.Background(), msg); err != nil {
log.Fatal("failed to commit message:", err)
}
}
}
func processMessage(msg kafka.Message) {
// 这里添加消息处理逻辑
log.Printf("message at topic/partition/offset %v/%v/%v: %s = %s\n", msg.Topic, msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
}
使用数据库记录偏移量, 确保消息处理的幂等性
为了确保即使在消息重复消费的情况下也不会导致数据问题, 我们需要确保消息处理逻辑是幂等的。这意味着无论消息被处理多少次, 结果都是相同的。
func saveOffsetToDB(topic string, partition int32, offset int64) {
// 这里添加将偏移量保存到数据库的逻辑
}
func loadOffsetFromDB(topic string, partition int32) int64 {
// 这里添加从数据库加载偏移量的逻辑
return 0 // 示例返回值
}
处理消费者重新平衡
在某些场景下时, 我们需要确保正确处理分区的分配和撤销。这可以通过自定义Balancer来完成。
type Balancer interface {
// Balance receives a message and a set of available partitions and
// returns the partition number that the message should be routed to.
//
// An application should refrain from using a balancer to manage multiple
// sets of partitions (from different topics for examples), use one balancer
// instance for each partition set, so the balancer can detect when the
// partitions change and assume that the kafka topic has been rebalanced.
Balance(msg Message, partitions ...int) (partition int)
}
func (rr *RoundRobin) Balance(msg Message, partitions ...int) int {
return rr.balance(partitions)
}
func (rr *RoundRobin) balance(partitions []int) int {
length := uint32(len(partitions))
offset := atomic.AddUint32(&rr.offset, 1) - 1
return partitions[offset%length]
}
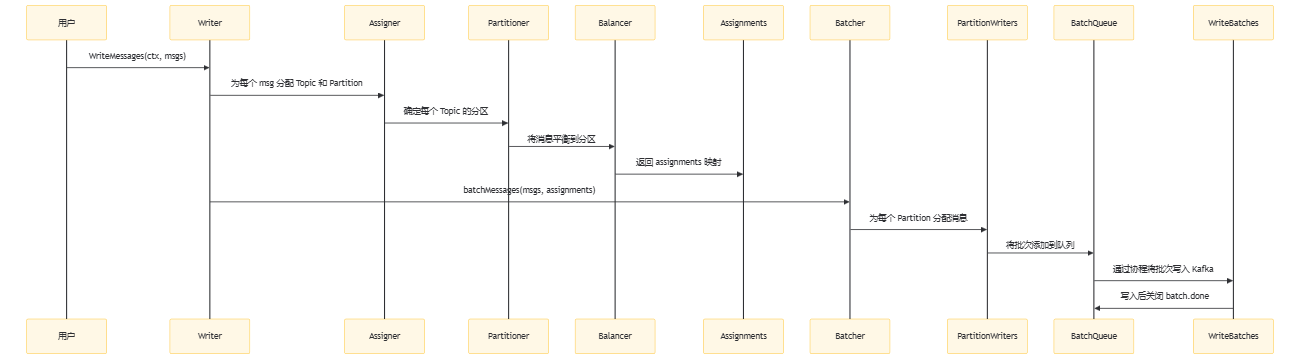
源码分析探讨提升写入吞吐
WriteMessages代码如下:
// When sending synchronously and the writer's batch size is configured to be
// greater than 1, this method blocks until either a full batch can be assembled
// or the batch timeout is reached. The batch size and timeouts are evaluated
// per partition, so the choice of Balancer can also influence the flushing
// behavior. For example, the Hash balancer will require on average N * batch
// size messages to trigger a flush where N is the number of partitions. The
// best way to achieve good batching behavior is to share one Writer amongst
// multiple go routines.
func (w *Writer) WriteMessages(ctx context.Context, msgs ...Message) error {
...
// We use int32 here to half the memory footprint (compared to using int
// on 64 bits architectures). We map lists of the message indexes instead
// of the message values for the same reason, int32 is 4 bytes, vs a full
// Message value which is 100+ bytes and contains pointers and contributes
// to increasing GC work.
assignments := make(map[topicPartition][]int32)
for i, msg := range msgs {
topic, err := w.chooseTopic(msg)
if err != nil {
return err
}
numPartitions, err := w.partitions(ctx, topic)
if err != nil {
return err
}
partition := balancer.Balance(msg, loadCachedPartitions(numPartitions)...)
key := topicPartition{
topic: topic,
partition: int32(partition),
}
//先根据msg和balance机制选择某个topic下的partition
assignments[key] = append(assignments[key], int32(i))
}
batches := w.batchMessages(msgs, assignments)
if w.Async {
return nil
}
done := ctx.Done()
hasErrors := false
for batch := range batches {
select {
case <-done:
return ctx.Err()
case <-batch.done:
if batch.err != nil {
hasErrors = true
}
}
}
...
}
batchMessages代码如下:
func (w *Writer) batchMessages(messages []Message, assignments map[topicPartition][]int32) map[*writeBatch][]int32 {
var batches map[*writeBatch][]int32
if !w.Async {
batches = make(map[*writeBatch][]int32, len(assignments))
}
w.mutex.Lock()
defer w.mutex.Unlock()
if w.writers == nil {
w.writers = map[topicPartition]*partitionWriter{}
}
// key: topic/partition; indexes: msg id
for key, indexes := range assignments {
writer := w.writers[key]
if writer == nil {
writer = newPartitionWriter(w, key)
w.writers[key] = writer
}
// 每一个partitionWriter都会维护一个batch, 当batch满时, 会flush到kafka
wbatches := writer.writeMessages(messages, indexes)
for batch, idxs := range wbatches {
batches[batch] = idxs
}
}
return batches
}
具体的攒批的逻辑如下:
- 初始化
partitionWriter, 启动一个携程等待写批次:
func newPartitionWriter(w *Writer, key topicPartition) *partitionWriter {
writer := &partitionWriter{
meta: key,
queue: newBatchQueue(10),
w: w,
}
// 启动一个携程写批
w.spawn(writer.writeBatches)
return writer
}
func (ptw *partitionWriter) writeBatches() {
for {
// 从队列中阻塞地获取一个batch
batch := ptw.queue.Get()
// The only time we can return nil is when the queue is closed
// and empty. If the queue is closed that means
// the Writer is closed so once we're here it's time to exit.
if batch == nil {
return
}
// 1. 调用 ptw.w.stats() 进行读写统计
// 2. 写批次: ptw.w.produce(key, batch)
// 3. close(b.done)
ptw.writeBatch(batch)
}
}
batchQueue使用的是sync.Cond的广播能力实现的阻塞队列:
func newBatchQueue(initialSize int) batchQueue {
bq := batchQueue{
queue: make([]*writeBatch, 0, initialSize),
mutex: &sync.Mutex{},
cond: &sync.Cond{},
}
bq.cond.L = bq.mutex
return bq
}
func (b *batchQueue) Get() *writeBatch {
b.cond.L.Lock()
defer b.cond.L.Unlock()
for len(b.queue) == 0 && !b.closed {
b.cond.Wait()
}
if len(b.queue) == 0 {
return nil
}
batch := b.queue[0]
b.queue[0] = nil
b.queue = b.queue[1:]
return batch
}
func (b *batchQueue) Put(batch *writeBatch) bool {
b.cond.L.Lock()
defer b.cond.L.Unlock()
defer b.cond.Broadcast()
if b.closed {
return false
}
b.queue = append(b.queue, batch)
return true
}
- 在同步模式下, 每一个
partitionWriter只会维护一个batch, 当batch满时, 会flush到kafka, 然后再用放回队列中:
func (ptw *partitionWriter) writeMessages(msgs []Message, indexes []int32) map[*writeBatch][]int32 {
ptw.mutex.Lock()
defer ptw.mutex.Unlock()
batchSize := ptw.w.batchSize()
batchBytes := ptw.w.batchBytes()
var batches map[*writeBatch][]int32
if !ptw.w.Async {
batches = make(map[*writeBatch][]int32, 1)
}
//indexes: msg id
for _, i := range indexes {
assignMessage:
batch := ptw.currBatch
if batch == nil {
batch = ptw.newWriteBatch()
ptw.currBatch = batch
}
// 判断是否可以加入到当前batch
if !batch.add(msgs[i], batchSize, batchBytes) {
batch.trigger() // close(b.ready)
ptw.queue.Put(batch)
ptw.currBatch = nil
goto assignMessage
}
// 判断是否需要flush
if batch.full(batchSize, batchBytes) {
batch.trigger() // close(b.ready)
ptw.queue.Put(batch)
ptw.currBatch = nil
}
if !ptw.w.Async {
batches[batch] = append(batches[batch], i)
}
}
return batches
}
3.1 newWriteBatch中的awaitBatch 实现等待批次的逻辑:
func (ptw *partitionWriter) newWriteBatch() *writeBatch {
batch := newWriteBatch(time.Now(), ptw.w.batchTimeout())
// 启动一个携程等待超时或者批次满了
ptw.w.spawn(func() { ptw.awaitBatch(batch) })
return batch
}
func (ptw *partitionWriter) awaitBatch(batch *writeBatch) {
select {
case <-batch.timer.C:
ptw.mutex.Lock()
// detach the batch from the writer if we're still attached
// and queue for writing.
// Only the current batch can expire, all previous batches were already written to the queue.
// If writeMesseages locks pw.mutex after the timer fires but before this goroutine
// can lock pw.mutex it will either have filled the batch and enqueued it which will mean
// pw.currBatch != batch so we just move on.
// Otherwise, we detach the batch from the ptWriter and enqueue it for writing.
if ptw.currBatch == batch {
ptw.queue.Put(batch)
ptw.currBatch = nil
}
ptw.mutex.Unlock()
case <-batch.ready:
// The batch became full, it was removed from the ptwriter and its
// ready channel was closed. We need to close the timer to avoid
// having it leak until it expires.
batch.timer.Stop()
}
}
总结一句, WriteMessages 是支持多携程并发的, 每个 partitionWriter 都维护一个 batch, 当 batch 满时, 会 flush 到 kafka, 为了提高性能, 我们可以使用多个发送者来共享这个writer。
后记
github.com/segmentio/kafka-go是一个纯Go语言实现的Kafka客户端库, 操作简单, 支持context。github.com/segmentio/kafka-go不支持幂等和事务, 需要结合业务自行实现。WriteMessages是支持多携程的, 可以看成一个长链接, 可以用多个Sender一起共享, 注意结合一些参数来调优性能。- 消费消息的时候, 可以结合一些参数来调优性能。